Дорогие друзья!
Поздравляю всех с наступающим Новым годом! Желаю в будущем году, как можно больше задач решать с помощью свободного программного обеспечения. Пусть оно приносит вам не только удовольствие и пользу, но и удачу. Желаю всем вам весь год заниматься тем, чем нравится!
До встречи в Новом году!
20081231
20081226
Русский BibTeX и XeLaTeX
К заметке о шрифтах OpenType в XeLaTeX добавляю примеры совместного использования русского языка, BibTeX и XeLaTeX, как вместе с
Первое, не очень красивое решение: использовать по-прежнему
Итак, предположим, что и документ, и библиография (bib-файл) набраны в уникоде (UTF-8) и содержат кириллические символы. Дальше есть два пути.
При использовании
Для использования
P.S. Также дополнил предыдущую заметку о XeLaTeX примером, как обеспечить одинаковый рост строчных букв разных гарнитур.
babel, так и вместе с polyglossia; смотрите PDF и его исходник.Внимание: всё нижеследующее относится к использованию XeLaTeX, а не обычного, проверенного временем LaTeX.Стандартное средство для работы с библиографией в LaTeX — BibTeX. Стандартное средство для «русификации» (включения нужных правил переноса, названий разделов, определённых типографических норм) — пакет
babel. Однако ни BibTeX, ни babel не умеют работать с уникодом. В результате при попытке использования этих средств в XeLaTeX могут быть проблемы. В частности, проблемы возникают при попытке использовать их одновременно: при наборе русских текстов с русской библиографией.Первое, не очень красивое решение: использовать по-прежнему
babel, но подставлять костыли, переопределяющие русские символы. Второе решение: перейти от babel к использованию более современного пакета polyglossia.Итак, предположим, что и документ, и библиография (bib-файл) набраны в уникоде (UTF-8) и содержат кириллические символы. Дальше есть два пути.
При использовании
babel в каталог с документом необходимо положить xecyr.sty, а в преамбуле поместить примерно такой код:\usepackage[cm-default]{fontspec} % or install lmodern
\usepackage{xltxtra} % load xunicode
\usepackage[russian]{babel}
\usepackage{xecyr}Компилировать с помощью xelatex, запуская bibtex как обычно.Для использования
polyglossia нужно установить пакеты etoolbox и polyglossia. Можно просто поместить файлы etoolbox.sty, polyglossia.ins и polyglossia.dtx из этих пакетов в каталог с документом и выполнить$ latex polyglossia.ins\usepackage[cm-default]{fontspec} % or install lmodern
\usepackage{xltxtra} % load xunicode
\usepackage[russian]{polyglossia}polyglossia довольно похожа на babel но имеет некоторые отличия. Чтобы переопределить название стандартного заголовка, например, списка литературы, можно использовать команду\gappto\captionsrussian{\renewcommand{\refname}{Мои ссылки}}P.S. Также дополнил предыдущую заметку о XeLaTeX примером, как обеспечить одинаковый рост строчных букв разных гарнитур.
Ярлыки:
русский язык,
latex,
UTF8

20081215
eeePC 901 и Debian (установка и настройка)
У моей жены теперь появился eeePC 901. Эту модель выбрали в основном потому, что в ней сочетается ещё достаточно компактный размер и малый вес (при этом экран уже 1024×600), ёмкий аккумулятор и экономичный процессор (это один из наиболее автономных нетбуков), при этом цена вполне разумна. Выбрали жизнерадостный зелёный вариант исполнения с предустановленным Linux (в этом случае второй встроенный флэш-диск 16 ГБ, а не 8 ГБ, как в версии с Windows).
Вообще, надо отметить, что мы, конечно, с самого начала планировали ставить на него полноценный дистрибутив, но всё равно меня очень огорчила неполная работоспособность предустановленного Xandros.
Всё дело в том, что в 901, 1000 и 1000H Асус стал ставить модуль WiFi Realtek RT2860, драйвер к которому довольно сырой и требует проприетарной прошивки. Как результат, eeePC 901 из коробки просто не мог подключиться к открытой (!) точке доступа (тоже Асус, кстати). Такой хоккей нам не нужен. Более того, я теперь не удивляюсь, что им где-то там возвращают машины с Linux. Даже такая базовая для нетбука вещь как WiFi из коробки в новых 901 толком не работает, и не работает по вине производителя. Очень, очень стыдно, Асус, мы в тебя верили, а ты явно предпочитаешь модели без Linux! Одно отрадно: за лицензию Windows платить не пришлось, а проблема с WiFi решаема.
Так что почти сразу появился стимул поставить нормальный Debian. Сразу скажу, что с установкой системы моя жена справилась самостоятельно. Я только подсказал, как загрузочный образ debian-eeepc.img записать на флэшку:
Для загрузки с установочной флэшки, нужно вставить флэшку, нажать ESC при перезагрузке устройства и выбрать устройство, с которого осуществлять загрузку. WiFi включается в BIOS (F2 при загрузке), это необходимо, если планируется ставить систему по беспроводной сети. Мы ставили по обычному Ethernet.
Основной источник информации при установке и настройке Debian на eeePC: Debian EeePC Wiki.
После установки почти всё сразу заработало. Ручного вмешательства потребовали только настройка sudo, WiFi и звук (микрофон). Засыпание/просыпание и видеокамера заработали сразу после установки. VGA-выход ещё не проверяли. Даже многопальцевые комбинации на тачпэде работают (хотя и не настраиваются, и мне кажутся непривычными после тачпэда synaptics). Bluetooth ещё не проверяли. Кардиридер работает.
sudo настраивается как обычно, запуском
Драйвер для WiFi доступен как на сайте производителя (Ralink), так и в репозитории
После установки
Вообще, попробовал wicd я совсем недавно, и должен сказать, что это наиболее логичная и ясная графическая конфигурялка сети, которую я пока что видел. Устанавливается созданием файла
Далее звук. Игрался он и так нормально, а вот с микрофона ничего не записывалось. Выяснилось, что поддержка Intel HDA Audio появилась в ALSA сравнительно недавно. Соответственно, нужно или ставить ядро 2.6.28-rc1 или более позднее, или собрать новую альзу самостоятельно. Мне было проще сделать второе.
Для сборки альзы, вначале устанавливаем
Аппаратные клавиши работают должным образом после установки пакета
Ещё остаётся задача как следует настроить тачпэд. В 901 используется тачпэд Elantech. У меня он сейчас настроен как
Дополнение 2009-03-07: см. также мою следующую заметку, как переназначить курсорные клавиши, Shift и PageUp/PageDown на ееePC 901.
Дополнение 2009-04-02: дополнил описанием, как пересобрать пакеты ALSA для Debian stable, как собрать пакет ядра 2.6.29, как настроить тачпэд Elantech.
Дополнение 2009-07-01: в свежей заметке — как бороться с тормозами Firefox-а на eeePC.
Дополнение 2009-07-09: упомянул
Вообще, надо отметить, что мы, конечно, с самого начала планировали ставить на него полноценный дистрибутив, но всё равно меня очень огорчила неполная работоспособность предустановленного Xandros.
Всё дело в том, что в 901, 1000 и 1000H Асус стал ставить модуль WiFi Realtek RT2860, драйвер к которому довольно сырой и требует проприетарной прошивки. Как результат, eeePC 901 из коробки просто не мог подключиться к открытой (!) точке доступа (тоже Асус, кстати). Такой хоккей нам не нужен. Более того, я теперь не удивляюсь, что им где-то там возвращают машины с Linux. Даже такая базовая для нетбука вещь как WiFi из коробки в новых 901 толком не работает, и не работает по вине производителя. Очень, очень стыдно, Асус, мы в тебя верили, а ты явно предпочитаешь модели без Linux! Одно отрадно: за лицензию Windows платить не пришлось, а проблема с WiFi решаема.
Так что почти сразу появился стимул поставить нормальный Debian. Сразу скажу, что с установкой системы моя жена справилась самостоятельно. Я только подсказал, как загрузочный образ debian-eeepc.img записать на флэшку:
0. посмотреть как называется устройство флэшки в выводе командыи подсказал ещё как лучше разбить диск (/ на первом флэш-диске, 4 ГБ, /home на втором, 16 ГБ, раздел для подкачки не создавали). Следуя рекомендации в Debian Wiki мы оставили два небольших раздела на первом флэш-диске. Вроде бы это ускоряет загрузку.mount,
1. отсоединить том флэшки,
2.dd if=debian-eeepc.img of=/dev/устройство_флэшки,
3.sync
Для загрузки с установочной флэшки, нужно вставить флэшку, нажать ESC при перезагрузке устройства и выбрать устройство, с которого осуществлять загрузку. WiFi включается в BIOS (F2 при загрузке), это необходимо, если планируется ставить систему по беспроводной сети. Мы ставили по обычному Ethernet.
Основной источник информации при установке и настройке Debian на eeePC: Debian EeePC Wiki.
После установки почти всё сразу заработало. Ручного вмешательства потребовали только настройка sudo, WiFi и звук (микрофон). Засыпание/просыпание и видеокамера заработали сразу после установки. VGA-выход ещё не проверяли. Даже многопальцевые комбинации на тачпэде работают (хотя и не настраиваются, и мне кажутся непривычными после тачпэда synaptics). Bluetooth ещё не проверяли. Кардиридер работает.
sudo настраивается как обычно, запуском
visudo от root-а, и добавлением строки username ALL=(ALL) ALL/etc/sudoers. Другой вариант, раскомментировать строчку %sudo ALL=NOPASSWD: ALLДрайвер для WiFi доступен как на сайте производителя (Ralink), так и в репозитории
deb http://eeepc.debian.net/debian lenny main contrib non-freeПосле установки
rt2860-modules-2.6.26-1-686 появляется возможность использовать сетевой интерфейс ra0. Разные способы настройки описаны здесь. Я же выбрал лёгкий путь и поставил wicd. Минутой позже я спокойно подключился к точке доступа с WPA2PSK.Вообще, попробовал wicd я совсем недавно, и должен сказать, что это наиболее логичная и ясная графическая конфигурялка сети, которую я пока что видел. Устанавливается созданием файла
/etc/apt/sources.list.d/wicd.list с указанием на сторонний репозиторий:deb http://apt.wicd.net lenny extraswget -q http://apt.wicd.net/wicd.gpg -O- | sudo apt-key add -wicd (с удалением NetworkManager). Запустить апплет wicd для панели Gnome: wicd-client.Далее звук. Игрался он и так нормально, а вот с микрофона ничего не записывалось. Выяснилось, что поддержка Intel HDA Audio появилась в ALSA сравнительно недавно. Соответственно, нужно или ставить ядро 2.6.28-rc1 или более позднее, или собрать новую альзу самостоятельно. Мне было проще сделать второе.
Дополнение 2009-04-02. Несколько слов о сборке ядра 2.6.29 для Debian. Хотя пакет этого ядра уже появился в репозиториях (sid), ставить его на eeePC 901 смысла нет: драйвер тачпэда Elantech в нём выключен, а поддержку WiFi-модуля в Debian-ядре вообще выкинули по лицензионным соображениям (см. баги #522078 и #521553).
Короче, поступать в этой ситуации следует так:
1) не устанавливать готовых пакетов Debian, а взять исходники ядра на kernel.org и собрать пакет самостоятельно; при этом получив и поддержку тачпэда, и поддержку WiFi, и ядро, оптимизированное для настольных приложений — «из коробки»; постарался отключить всё лишнее, но явно отключил не всё. Конфигурацию ядра я частично позаимствовал отсюда. Основные особенности:CONFIG_PREEMPT=y(десктоп),CONFIG_RT2860=y(встроенный WiFi),CONFIG_MOUSE_PS2_ELANTECH=y(тачпэд Elantech),CONFIG_ATL1E(гигабитный Ethernet);
2) следовать инструкциям по сборке собственного пакета с ядром; если кратко, то переходим в каталог с распакованными исходниками ядра и делаем следующее:$ make menuconfigНе забываем перед этим установить
$ make-kpkg clean
$ nice -n +10 fakeroot make-kpkg --initrd --revision=eee901 kernel_image kernel_headerskernel-packageиzlib1g-dev;
3) переходим на один каталог выше и устанавливаем собранные пакеты:$ cd ..
$ sudo dpkg -i linux-headers-*.deb linux-image-*.deb
4) Перед тем, как перезагрузиться, не забываем пересобрать те модули, которые ставились из исходников. Например, пересобрать пользовательские модули ALSA изalsa-sourceможно так:sudo nice -n +10 m-a a-i -l 2.6.29 alsaХотя, кстати, с 2.6.29 я уже не уверен, что это нужно. Спросите экспертов;
5) после перезагрузки у меня вроде всё заработало (о настройке тачпэда см. ниже): WiFi, двухпальцевых скроллинг на тачпэде, звук и запись звука, видеокамера, кардридер, блутус (встроенный Bluetooth ещё не проверял, внешний USB-модуль работает), засыпание-просыпание, датчики батареи.
Для сборки альзы, вначале устанавливаем
linux-headers:sudo aptitude install linux-headers-`uname -r`$ ./configure --with-cards=hda-intel
$ make
$ sudo make install-modules
$ sudo ./snddevicesДополнение 2009-04-02: правильный для Debian способ заключается в пересборке пакетов ALSA. Тогда драйвера не будут затираться при каждом апгрейде ALSA в дистрибутиве. Конкретно в этом случае, если система Lenny (stable), а нужная версия доступна только в Sid (unstable), я поступил так:
1) добавил репозиторий исходников sid в/etc/apt/sources.list:# sid source repositoryи вполнил
deb-src http://ftp.debian.org/debian sid main contrib non-freesudo aptitude update.
2) во временном каталоге выполнил$ apt-get -t sid source alsa-baseт.е. вытащил все исходники пакета alsa из репозитория sid. Затем скачал и установил все необходимые для сборки зависимости:$ sudo apt-get -t sid build-dep alsa-baseМожно сохранить где-нибудь список, чтобы было проще удалить их потом. Наконец, перешёл в каталог с пакетом:$ cd alsa-driver-1.0.19.dfsg/Конкретная версия может отличаться.
3) Редактирую файл списка изменений$ vi debian/changelogНа самом деле просто добавил «~backport1» к номеру версии. Новую запись в файлеchangelogделаю по образцу предыдущих (сохраняю отступы и количество пробелов). Время в нужном формате печатает командаdate -R.
4) Пересобираю пакеты:$ fakeroot dpkg-buildpackage -us -ucПерехожу на каталог выше и устанавливаю все собранные пакеты:$ cd ..Почти готово.
$ sudo dpkg -i linux-sound-base_1.0.19.dfsg-2~backport1_all.deb \
alsa-base_1.0.19.dfsg-2~backport1_all.deb \
alsa-source_1.0.19.dfsg-2~backport1_all.deb
5) Осталось собственно собрать модули для текущей версии ядра. Для этого должен быть установлен пакетlinux-headersиmodule-assistant. Тогда сборка и установка будет практически автоматической:$ sudo m-a a-i alsaВсё. Теперь «правильная» альза должна быть установлена «правильным» способом. И пока в stable не появится более свежей альзы, будет использоваться «бэкпорт». При обновлении ядра нужно будет повторить только последний шаг (5). Чтобы новые модули заработали, нужно или выгрузить вручную все старые модули, которые начинаются наsnd..., или просто перезагрузиться.
Аппаратные клавиши работают должным образом после установки пакета
eeepc-acpi-scripts из указанного выше специального репозитория Debian для eeePC. Опять же, при установке со специального образа, он устанавливается по-умолчанию.Ещё остаётся задача как следует настроить тачпэд. В 901 используется тачпэд Elantech. У меня он сейчас настроен как
Section "InputDevice"и он вроде работает. Кажется, только, иногда подтормаживает. Двумя пальцами делается вертикальная прокрутка и эмулируется средняя кнопка мыши, тремя пальцами эмулируется правая кнопка мыши, краткое касание второго пальца при удержании первого включает режим перетаскивания. Эти комбинации работают, но после тачпэда synaptics кажутся непривычными, и некоторые из них я бы отключил, особенно перетаскивание. На первое время я убавил чувствительность тачпэда в настройках Gnome.
Identifier "Configured Mouse"
Driver "mouse"
EndSection
Дополнение 2009-04-02: если было установлено достаточно свежее ядро с поддержкой тачпэдов Elantech (см. выше инструкции по установке ядра 2.6.29), то можно использовать нормальный драйвер тачпэда. Соответственно вСсылки по теме:Народный опыт (*nix на схожих моделях):/etc/X11/xorg.confпомещаем:Section "InputDevice"Кроме этого нужно установить
Identifier "Configured Mouse"
Driver "synaptics"
Option "Device" "/dev/input/mouse0"
Option "Protocol" "auto-dev"
Option "SHMConfig" "true"
Option "VertTwoFingerScroll" "1"
Option "HorizTwoFingerScroll" "1"
Option "TapButton1" "1"
Option "TapButton2" "2"
Option "TapButton3" "3"
EndSectionxserver-xorg-input-synapticsверсии не ниже 0.99.3. Готовые пакеты для Debian Lenny (stable) можно взять здесь. После перезапуска иксов, будет работать как вертикальный, так и горизонтальный скролинг двумя пальцами на тачпэде.
Подробности о настройке тачпэда смотрим в DebianEeePc Wiki.
- Ubuntu 8.04 Hardy на eeePC 1000H (ⓒ passshok)
- Fedora 10 на eeePC 1000H (ⓒ Tigro)
- openSUSE 11, Fedora 10, Debian testing, FreeBSD 8 на Acer Aspire One (ⓒ hrafn)
- Gentoo на eeePC 901 (ⓒ TheMixa)
- openSUSE 1.1 на MSI Wind U100 (ⓒ magik)
Дополнение 2009-03-07: см. также мою следующую заметку, как переназначить курсорные клавиши, Shift и PageUp/PageDown на ееePC 901.
Дополнение 2009-04-02: дополнил описанием, как пересобрать пакеты ALSA для Debian stable, как собрать пакет ядра 2.6.29, как настроить тачпэд Elantech.
Дополнение 2009-07-01: в свежей заметке — как бороться с тормозами Firefox-а на eeePC.
Дополнение 2009-07-09: упомянул
CONFIG_ATL1E (гигабитный Ethernet). Убрал ссылки на конфиг ядра, в котором его не было.
20081209
Пример рисования в PyCairo
Пробуя библиотеку для рисования Cairo из Python, сделал такую вот табличку:
У кого браузер не поддерживает SVG, сморим PNG.
Идею нарисовать временную шкалу использования языков программирования дал мне вот этот опрос на StackOverflow («В каком возрасте вы начали программировать?»).
Кто хочет себе такую же табличку (в смысле, аналогичную), скрипт к вашим услугам (Public Domain). Требует PyCairo (
Оказалось, рисовать из Python в Cairo очень просто. При этом можно получать изображения в векторном формате (PDF, PostScript, SVG), не говоря уже о PNG. Можно будет использовать в будущем для автоматизированного создания схем и графиков, если готовых программ вдруг не хватит.
Есть самоучитель Cairo Tutorial (тоже на примере Python). Если очень кратко, то это делается так:
Шаг 1. Импортируем модуль:
Шаг 2. Создаём «поверхность» и берём из неё «контекст» для рисования. Я рисовал сразу в SVG файл:
Шаг 3. Рисуем, используя контекст:
Шаг 4. Нарисовавшись всласть, сохраняем результат (закрываем «поверхность»):
У кого браузер не поддерживает SVG, сморим PNG.
Идею нарисовать временную шкалу использования языков программирования дал мне вот этот опрос на StackOverflow («В каком возрасте вы начали программировать?»).
Кто хочет себе такую же табличку (в смысле, аналогичную), скрипт к вашим услугам (Public Domain). Требует PyCairo (
python-cairo).Оказалось, рисовать из Python в Cairo очень просто. При этом можно получать изображения в векторном формате (PDF, PostScript, SVG), не говоря уже о PNG. Можно будет использовать в будущем для автоматизированного создания схем и графиков, если готовых программ вдруг не хватит.
Есть самоучитель Cairo Tutorial (тоже на примере Python). Если очень кратко, то это делается так:
Шаг 1. Импортируем модуль:
import cairo
Шаг 2. Создаём «поверхность» и берём из неё «контекст» для рисования. Я рисовал сразу в SVG файл:
svg=cairo.SVGSurface("имяфайла.svg",ширина_в_пунктах,высота_в_пунктах)
ctx=cairo.Context(svg)Шаг 3. Рисуем, используя контекст:
ctx.set_line_width(ширина_линии) # выбираем линию
ctx.set_source_rgba(красный,зелёный,синий,прозрачность) # выбираем цвет
ctx.move_to(x,y) # перемещаем «курсор»
ctx.line_to(x2,y2) # рисуем линию от позиции «курсора» до x2,y2
ctx.arc(x,y,радиус,угол1,угол2) # рисуем дугу с центром в (x,y)
ctx.close_path() # замыкаем контур
ctx.fill() # заливаем контур выбранным цветом
ctx.stroke() # обводим контур выбранной линией
ctx.set_font_size(размер_шрифта) # выбираем размер шрифта, можно дробный
ctx.show_text("буквы") # пишем слово «буквы»
Шаг 4. Нарисовавшись всласть, сохраняем результат (закрываем «поверхность»):
svg.finish()В качестве справки используем документацию по Cairo для языка Си. Изменения для Python-скриптов вполне очевидны: вместо передачи параметров
cairo_t *cr используем методы объекта-контекста. Аналогично для поверхностей.
Ярлыки:
визуализация данных,
графика,
личное,
программирование,
python
20081206
Диссертация в LaTeX
Мой коллега-блоггер Миша Конник задумал титанический труд на тему «Как написать диплом в LaTeX». Который по задумке должен стать циклом статей, охватывающий вопросы от установки до вёрстки в LaTeX. Некоторые статьи уже готовы. Кстати, один подобный цикл статей, но более общего характера, уже существует.
Мне лично представляется, что при такой широте охвата материала работа эта необъятная. И если это будет коллективная работа, то место ей в Викиучебниках. Особенно в том, что касается вёрстки в LaTeX. Слишком много возможностей, слишком разные у всех задачи и тексты. Вопросы же установки и настройки во многом зависят от используемой ОС и используемого дистрибутива LaTeX. Остаются вопросы специфичные для написания именно диплома (или подобных работ: курсовых, диссертаций, отчётов). Я же в своём блоге стараюсь разрешать конкретные, частные вопросы.
В этой заметке я поделюсь кое-каким опытом написания кандидатской диссертации в LaTeX. Многое пригодится и тем, кто пишет дипломы. Писал я её три года назад, пользовался тогда teTeX (теперь TeXLive). Однако почти всё должно работать и сейчас. Во всяком случае, мой исходник по-прежнему компилируется PDFLaTeX. Об использовании русского языка в PDFLaTeX см. эту заметку. Не утверждаю, что всё сделал правильно или наилучшим образом. Очень может быть, что для ряда задач появились с тех пор лучшие решения.
Оставлю также в стороне нетехнические вопросы: что писать, как писать и как организовать работу. Вот тут есть некоторые рекомендации (на английском), многое применимо и в отечественных условиях.
Из технических вопросов, можно выделить:
В плане размера шрифтов, межстрочного интервала* и полей я полагался на настройки пакета dissert.cls. Однако эти вещи легко настраиваются и вручную, см. заметки изменение межстрочного интервала в LaTeX и как задать поля страницы в LaTeX.
Переопределение формата нумерации в списке литературы:
Для организации иллюстраций несколько в одной я использовал пакет
Шаблон же основной части документа у меня был такой:
В будущем, возможно, я дополню эту заметку особенностями набора математики (пока можно обратиться к примерам К. Воронцова), некоторыми особенностями набора автореферата (который набирается на формате A5) и шаблоном титульного листа.
Хотя этот текст распространяется, как обычно в моём блоге, по лицензии CC-BY-NC-SA (т.е. со ссылкой на советы.блогспот.ком и не для коммерческого использования), но если кто-то хочет использовать его в Викиучебниках или других проектах Wikimedia Foundation, то в этом случае можно распространять на условиях GFDL.
Дополнение 2009-10-18: нашёл ещё серию статей Павла Самолысова «Верстаем диплом в LaTeX». Может кому пригодится.
Мне лично представляется, что при такой широте охвата материала работа эта необъятная. И если это будет коллективная работа, то место ей в Викиучебниках. Особенно в том, что касается вёрстки в LaTeX. Слишком много возможностей, слишком разные у всех задачи и тексты. Вопросы же установки и настройки во многом зависят от используемой ОС и используемого дистрибутива LaTeX. Остаются вопросы специфичные для написания именно диплома (или подобных работ: курсовых, диссертаций, отчётов). Я же в своём блоге стараюсь разрешать конкретные, частные вопросы.
В этой заметке я поделюсь кое-каким опытом написания кандидатской диссертации в LaTeX. Многое пригодится и тем, кто пишет дипломы. Писал я её три года назад, пользовался тогда teTeX (теперь TeXLive). Однако почти всё должно работать и сейчас. Во всяком случае, мой исходник по-прежнему компилируется PDFLaTeX. Об использовании русского языка в PDFLaTeX см. эту заметку. Не утверждаю, что всё сделал правильно или наилучшим образом. Очень может быть, что для ряда задач появились с тех пор лучшие решения.
Оставлю также в стороне нетехнические вопросы: что писать, как писать и как организовать работу. Вот тут есть некоторые рекомендации (на английском), многое применимо и в отечественных условиях.
Из технических вопросов, можно выделить:
- Вопросы соответствия требованиям по оформлению работы (как правило, они определяют используемый шрифт, макет страницы, отступы, порядок нумерации объектов, страниц, формат подписей, макет титульной страницы); тут лучше положиться на советы своего научного руководителя.
В случае диссертаций, в соответствии с Положением о порядке присуждения ученых степеней, утверждены формы титульных листов диссертации и автореферата, а оформление диссертации «должно соответствовать требованиям, устанавливаемым Министерством образования Российской Федерации»
- Вопросы соответствия нормам отечественной полиграфии (не секрет, что ЛаТэХ по-умолчанию набирает «по-американски», в том числе формулы и математику), тут для начала можно посмотреть примеры правильного набора у К. Воронцова; вот некоторые из отличий:
- кавычки у нас используются французские или немецкие;
- иначе набирается тире (во всех случаях);
- отличается ряд математических символов, например, знаки нестрогих неравенств;
- используется другое начертание греческих букв;
- отличаются обозначения ряда функций и ряд других математических обозначений;
- знак «равно» дублируется при разрыве формулы на две строки;
- первый абзац набирается тоже с отступом;
- кавычки у нас используются французские или немецкие;
- Оформление списка литературы регламентируется соответствующими ГОСТами. С 2009-го года, кстати, вступает в действие новый ГОСТ Р 7.0.5-2008. Думаю, обновлённые стили BiBTeX скоро появятся.
Лирическое отступление. Эта статья написана для блога советы.блогспот.ком и распространяется на условиях лицензии CC-BY-NC-SA 3.0, т. е. требует ссылки на оригинал и запрещает коммерческое использование текста.
В своей работе я использовал класс документа dissert.cls. Теперь его первоисточник что-то не находится, так что выкладываю ту версию, которую использовал сам. Однако очень может быть, что класс rusthesis.cls и лучше. Я его не пробовал. Есть ещё пакет disser, который служит тем же целям. Его я тоже не пробовал.В плане размера шрифтов, межстрочного интервала* и полей я полагался на настройки пакета dissert.cls. Однако эти вещи легко настраиваются и вручную, см. заметки изменение межстрочного интервала в LaTeX и как задать поля страницы в LaTeX.
*) Да, я считаю, что полуторный, а тем более двойной, интервал — это некрасиво, разве что удобно, чтобы делать правки на бумаге. Однако таков жанр.Набирал текст я в кодировке CP1251, в основном с расчётом на то, чтобы в процессе работы можно было спокойно давать исходник пользователям Windows. Однако это практически не потребовалось.
\usepackage[cp1251]{inputenc}
\usepackage[russian]{babel}
\usepackage[T2A]{fontenc}Также я пользовался пакетом шрифтов pscyr, пользоваться которым я, однако, не рекомендую, по причине неясной лицензии на распространение этих шрифтов. К счастью, свободно-распространяемых шрифтов с тех пор прибавилось.Переопределение формата нумерации в списке литературы:
\makeatletterНадпись «Стр.» над номерами страниц в таблице с оглавлением (только для класса документа
\renewcommand\@biblabel[1]{#1.}
\makeatother
dissert.cls):\renewcommand\contentsdesc{Стр.}Первый абзац с отступом:\usepackage{indentfirst}Далее, я переопределял формат подписей под иллюстрациями:%different caption style: ``Fig.~N.~Caption text''Также я использовал пакет hangcaption, чтобы обеспечить «висящие» номера иллюстраций. Это выглядело примерно так:
\makeatletter
\long\def\@makecaption#1#2{%
\vskip\abovecaptionskip
\sbox\@tempboxa{#1.~#2}%
\ifdim \wd\@tempboxa >\hsize
#1.~#2\par
\else
\global \@minipagefalse
\hb@xt@\hsize{\hfil\box\@tempboxa\hfil}%
\fi
\vskip\belowcaptionskip}
\makeatother
Я также включал макрос
________________
,́ `.
| |
| @}---,--`-- |
| |
`.________________,'
Рис. 1.1. Что значит имя? Роза пахнет розой,
хоть розой назови её, хоть нет.
\reversemarginpar, поскольку широким в диссертации является именно левое поле.Для организации иллюстраций несколько в одной я использовал пакет
subfigure. Соответственно, чтобы включить нумерацию внутренних элементов иллюстрации русскими буквами («Рис. 3.14 (д)»):\renewcommand{\thesubfigure}{(\asbuk{subfigure})~}Я опущу все макросы, касающиеся набора математики. С высокой вероятностью, у моих читателей они будут другие.Шаблон же основной части документа у меня был такой:
\begin{document}
\tableofcontents
\clearpage
\include{intro}
\clearpage
\include{ch02}
\clearpage
\include{ch03}
\clearpage
\chapter*{Заключение}
\addcontentsline{toc}{chapter}{Заключение}
Текст заключения.
\clearpage
\listoffigures
\addcontentsline{toc}{chapter}{Список иллюстраций}
\clearpage
\listoftables
\addcontentsline{toc}{chapter}{Список таблиц}
\clearpage
\renewcommand{\bibname}{Список использованных источников}
\addcontentsline{toc}{chapter}{Список использованных источников}
\bibliographystyle{gost71u}
\bibliography{thesis}
\end{document}Как можно заметить, я вынес все главы в отдельные файлы (вообще, такой подход можно рекомендовать для набора любых больших документов). Правильные заголовки всяких «списков» в оглавление вносил вручную (команды \addcontentsline). Ещё изменил название списка литературы. А формат списка литературы определил с помощью стиля BiBTeX gost71. В случае, если это не годится, можно создать собственный стиль BiBTeX.В будущем, возможно, я дополню эту заметку особенностями набора математики (пока можно обратиться к примерам К. Воронцова), некоторыми особенностями набора автореферата (который набирается на формате A5) и шаблоном титульного листа.
Хотя этот текст распространяется, как обычно в моём блоге, по лицензии CC-BY-NC-SA (т.е. со ссылкой на советы.блогспот.ком и не для коммерческого использования), но если кто-то хочет использовать его в Викиучебниках или других проектах Wikimedia Foundation, то в этом случае можно распространять на условиях GFDL.
Дополнение 2009-10-18: нашёл ещё серию статей Павла Самолысова «Верстаем диплом в LaTeX». Может кому пригодится.
Ярлыки:
наука,
русский язык,
latex
20081203
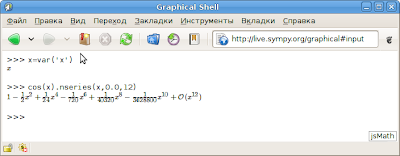
Символьные вычисления в SymPy онлайн
Интерактивная демо-сессия SymPy: live.sympy.org. Теперь любой желающий сразу может попробовать в действии эту библиотеку для компьютерной алгебры в Python.
Также может пригодится как символьный веб-калькулятор :) Там же есть и графическая версия консоли, в которой формулы отрисовываются как в LaTeX.
Также может пригодится как символьный веб-калькулятор :) Там же есть и графическая версия консоли, в которой формулы отрисовываются как в LaTeX.

Ярлыки:
наука,
ссылки,
численные методы,
python
20081201
XeLaTeX и шрифты OpenType в LaTeX
Использовать нестандартные гарнитуры в традиционном LaTeX не так-то просто. Практически, необходимо иметь отдельный пакет LaTeX для каждой новой гарнитуры. Для ряда распространённых гарнитур такие пакеты есть. А если хочется нестандартную гарнитуру, для которой нет стандартного пакета?
Легко использовать любые современные шрифты TrueType и OpenType позволяет XeLaTeX.
Вначале нужно установить XeLaTeX. В Debian/Ubuntu для этого достаточно поставить пакет
Помимо этого, нужно определиться собственно с используемыми шрифтами. XeLaTeX может использовать любые шрифты, которые может использовать Fontconfig. Просмотреть список установленных в системе шрифтов и их имена можно с помощью команды
Далее создаём документ LaTeX, как обычно. В преамбулу добавляем:
Как я понял,
Затем можно задать стандартные шрифты документа:
Компилировать нужно с помощью
пример использования (исходник, UTF-8)
пример использования (PDF)
Да, очень рекомендую посмотреть на что способен XeLaTeX, если ему дать хороший шрифт. Вот только где бы ещё лицензионных (свободно распространяемых) русских шрифтов найти…
Дополнение: XeLaTeX не совместим с пакетом
Дополнение 20081226: выкладываю также примеры использования BibTeX совместно с XeLaTeX для написания русскоязычных текстов. Рассмотрены оба способа: и с
Легко использовать любые современные шрифты TrueType и OpenType позволяет XeLaTeX.
Вначале нужно установить XeLaTeX. В Debian/Ubuntu для этого достаточно поставить пакет
texlive-xetex.Помимо этого, нужно определиться собственно с используемыми шрифтами. XeLaTeX может использовать любые шрифты, которые может использовать Fontconfig. Просмотреть список установленных в системе шрифтов и их имена можно с помощью команды
fc-list: $ fc-list | grep Inconsolata
Inconsolata:style=Medium~/.fonts/.Далее создаём документ LaTeX, как обычно. В преамбулу добавляем:
\usepackage[cm-default]{fontspec}
\usepackage{xunicode}
\usepackage{xltxtra}
Главный пакет тут — fontspec. Опция cm-default необходима, чтобы он не пытался использовать шрифты lmodern (которые в Debian/Ubuntu надо ставить отдельно, а русских глифов в них всё равно нет).Как я понял,
xunicode изменяет традиционнее латэховские макросы вроде \" таким образом, что немецкую «о умляют» (ö) в XeLaTeX можно ввести не только напрямую с клавиатуры как ö, но и как обычно, \"o. Вообще, все уникодные символы можно вводить непосредственно с клавиатуры (например, с помощью клавиши Compose). Это удобно. Пакет xltxtra добавляет чудесный макрос \XeLaTeX. Затем можно задать стандартные шрифты документа:
\setromanfont{Charis SIL}
\setsansfont{Liberation Sans}
\setmonofont{Inconsolata}В общем-то, названия этих команд говорит сами за себя. Они меняют шрифт всего документа в целом. Есть ещё команда \setmainfont{Имя шрифта}.Дополнение 20081226: поскольку рост строчных букв у разных гарнитур одного кегля разнится, то при совместном использовании в пределах одного абзацах их необходимо соответствующим образом масштабировать. Для того, чтобы обеспечить одинаковый росит строчных букв, можно задать глобальную опцию:Временное переключение гарнитуры делается командой\defaultfontfeatures{Scale=MatchLowercase}Можно, конечно, задавать опцию Scale для каждой гарнитуры отдельно. Аналогичная опцияScale=MatchUppercaseпозволяет обеспечить единый рост заглавных букв разных гарнитур.
\fontspec{Имя шрифта} в теле документа.Компилировать нужно с помощью
xelatex вместо latex. А так — как обычно. Получается PDF. Всё на удивление просто. Примеры по ссылкам. Инструкции в примерах немного более подробные, чем в этой заметке.пример использования (исходник, UTF-8)
пример использования (PDF)
Да, очень рекомендую посмотреть на что способен XeLaTeX, если ему дать хороший шрифт. Вот только где бы ещё лицензионных (свободно распространяемых) русских шрифтов найти…
Дополнение: XeLaTeX не совместим с пакетом
babel. Можно или пользоваться дополнительным пакетом xecyr, переопределяющий кириллический символы LaTeX в соответствии с уникодом, или пользоваться пакетом polyglossia, заменяющим babel. Спасибо Shender-у за подсказанные решения.Дополнение 20081226: выкладываю также примеры использования BibTeX совместно с XeLaTeX для написания русскоязычных текстов. Рассмотрены оба способа: и с
babel+xecyr, и с polyglossia.
20081129
Извлечение изображений из документов MS Word
Увы, иногда приходится получать вместо нормального файла изображения документ Word со вставленной в него картинкой. Короткий рецепт, как эту картинку из документа вытащить и получить в виде файла.
1. Открываем документ Word в OpenOffice Writer
2. Сохраняем в формате OpenDocument (.odt)
3. Переименовываем сохранённый файл, изменяя разрешение .odt на .zip (документы OpenOffice, на самом деле, простые zip-архивы)
4. Раскрываем zip-архив и берём готовые файлы изображений из папки Pictures/
1. Открываем документ Word в OpenOffice Writer
2. Сохраняем в формате OpenDocument (.odt)
3. Переименовываем сохранённый файл, изменяя разрешение .odt на .zip (документы OpenOffice, на самом деле, простые zip-архивы)
4. Раскрываем zip-архив и берём готовые файлы изображений из папки Pictures/
Ярлыки:
openoffice
20081127
Подключаем сетевой принтер в GNOME
Задача: подключить сетевой принтер к клиентской машине. Предполагается, что используется GNOME в Debian/Ubuntu.
Решение:
1. Запускаем утилиту настройки принтеров (Система → Администрирование → Печать из меню GNOME или
2. Указываем отображать принтеры, подключенные к другим машинам (Сервер → Параметры в утилите настройки, ставим нужную галочку).
3. В появившемся списке принтеров выбираем принтер по-умолчанию (правой кнопкой из контекстного меню). Чтобы напечатать пробную страницу, дважды щёлкаем по принтеру, и в его свойствах выбираем «Пробная страница».
Вот, в общем, и всё.
Решение:
1. Запускаем утилиту настройки принтеров (Система → Администрирование → Печать из меню GNOME или
sudo system-config-printer).2. Указываем отображать принтеры, подключенные к другим машинам (Сервер → Параметры в утилите настройки, ставим нужную галочку).

3. В появившемся списке принтеров выбираем принтер по-умолчанию (правой кнопкой из контекстного меню). Чтобы напечатать пробную страницу, дважды щёлкаем по принтеру, и в его свойствах выбираем «Пробная страница».

Вот, в общем, и всё.
Ярлыки:
настройка,
начинающим,
debian,
gnome,
ubuntu
20081126
Массовое резервное копирование репозиториев Mercurial
Лёгкость создания репозиториев в системе контроля версий Mercurial (
Соответственно, мой велосипед для резервного копированя всех имеющихся в рабочем каталоге репозиториев имеет два колеса:
По сути скрипт делает две вещи: создаёт (предположительно уникальное) имя для резервной копии репозитория, исходя из его положения на диске, и дальше либо делает клон существующего, удаляет копию, если она уже есть, и клонирует туда заново. Можно же просто копировать. Благо,
Использовать так:
hg) приводит к тому, что начинаешь использовать контроль версий для всего подряд, и количество маленьких репозиториев быстро растёт. При этом они могут лежать где угодно. Соответственно, иногда целесообразно все созданные репозитори ① найти и ② сохранить на будущее. Нахожу по наличию каталога .hg в корне каждого репозитория. Сохранять можно клонированием или простым копированием.Соответственно, мой велосипед для резервного копированя всех имеющихся в рабочем каталоге репозиториев имеет два колеса:
find, чтобы найти ①, и небольшой скрипт backup-hg-repo, чтобы собственно сделать бэкап ②:По сути скрипт делает две вещи: создаёт (предположительно уникальное) имя для резервной копии репозитория, исходя из его положения на диске, и дальше либо делает клон существующего, удаляет копию, если она уже есть, и клонирует туда заново. Можно же просто копировать. Благо,
hg это позволяет (если, конечно, в репозиторий, никто не пишет).#!/bin/sh
# usage: $0 path-to-hg-repository backup-directory
REPO="$1"
BACKUPDIR="$2"
if [ "x$BACKUPDIR" = "x" ] ; then
echo 'specify backup dir'
exit 1
fi
if [ ! -d "$BACKUPDIR" ] ; then
echo "$BACKUPDIR does not exist"
exit 2
fi
BACKUP="$BACKUPDIR/$(dirname "$REPO" | sed 's/^\.\///;s/\/$//;s/[\/_ ]/-/g')/"
REPO=$(dirname "$REPO")
# delete backup repo if it exists
hg status "$BACKUP" && rm -rf "$BACKUP"
hg clone "$REPO" "$BACKUP"
# or copy instead of cloning (if nobody is pushing to $REPO,
# see http://www.selenic.com/mercurial/wiki/index.cgi/BackUp)
# cp -r "$REPO" "$BACKUP"
Использовать так:
$ find . -name '.hg' -type d -exec backup-hg-repo '{}' /путь/по/которому/сохранять/бэкапы \;pull (думаю, это будет быстрее, но не так железобетонно-автоматически, как полный клон), или делать hg bundle -a "$BACKUPDIR/$(dirname ${REPO}).hg" (один сжатый файл истории будет занимать меньше места, но этот способ не сохраняет дополнительные файлы репозитория, вроде hgrc и не совместим с некоторыми расширениями).
Ярлыки:
командная строка,
программирование,
скрипт,
vcs
20081125
Вставка Python-кода в Vim
Как известно, в пайтоне отступ слева («indentation») синтаксически важен. Есть две школы мысли, как набирать его в тексте: табуляциями (количество табуляций — уровень отступа) или пробелами (в этом случае редактор должен обеспечивать раскрытие табуляций до нужного числа пробелов). Главное, эти способы не смешивать.
С одной стороны, я сторонник табуляций, их ширину в редакторе всегда легко изменить, не трогая кода. С другой — Style Guide for Python Code рекомендует делать отбивку четырьмя пробелами. В новых программах я стал использовать четыре пробела, в старых использую табуляции.
Собственно, проблемы здесь две. Первая неспецифична для пайтона, а проявляется всегда при вставке в Vim, запущенный в терминале. Vim попытается автоматически отбить вставляемый код ещё раз. Решение я уже описывал.
Вторая проблема специфична для пайтона. Даже если код был вставлен правильно (с сохранением авторских отступов), но авторские отступы не совпадают с используемыми в программе, код либо не будет работать вообще, либо будет работать неправильно. Выравнивать код с помощью
Выход здесь довольно прост:
P.S. Как легко заметить, пайтон не поощряет повторное использование в стиле copy-paste ;-)
С одной стороны, я сторонник табуляций, их ширину в редакторе всегда легко изменить, не трогая кода. С другой — Style Guide for Python Code рекомендует делать отбивку четырьмя пробелами. В новых программах я стал использовать четыре пробела, в старых использую табуляции.
Проблемы начинаются при попытке вставить чужой код в свой проект. С высокой степенью вероятности, он или использует другой способ ввода отступов, или другую ширину отступа.Лирическое отступление
В целом, в Vim набирать код Python удобно: поддерживается как режим с табуляциями, так и режим с пробелами. В последнем случае нужно установить опциюexpandtab. Автоматические отступы для Python поддерживаются.
Часто пригождается: чтобы сдвинуть блок текста влево или вправо:Shift-V, выделение блока,<<или>>соответственно.
Задать желаемую ширину табуляции и ширину сдвига можно опциямиtabstopиshiftwidthсоответственно, например:Настройки файла можно прописать в его:set ts=4 sw=4modeline.
Собственно, проблемы здесь две. Первая неспецифична для пайтона, а проявляется всегда при вставке в Vim, запущенный в терминале. Vim попытается автоматически отбить вставляемый код ещё раз. Решение я уже описывал.
:set paste.Вторая проблема специфична для пайтона. Даже если код был вставлен правильно (с сохранением авторских отступов), но авторские отступы не совпадают с используемыми в программе, код либо не будет работать вообще, либо будет работать неправильно. Выравнивать код с помощью
<< и >> далеко не всегда удобно.Выход здесь довольно прост:
- (опционально) временно отключить
expandtab, если используется; - преобразовать авторские пробелы в табуляции, для этого выделяем нужный блок и делаем
:retab!5, где аргумент («5») — авторская ширина отступа; - (опционально) при использовании
expandtab, включить его обратно, а «авторские» табуляции заменить на нужное число пробелов (:s#\t# #g).
P.S. Как легко заметить, пайтон не поощряет повторное использование в стиле copy-paste ;-)
Ярлыки:
программирование,
python,
vim
20081121
XPDF для предварительного просмотра LaTeX
При редактировании документов LaTeX я обычно пользуюсь для предварительного просмотра
Вот ещё несколько менее известных, но полезных при таком использовании
xpdf. Несмотря на его спартанский интерфейс, тому есть пара весомых причин:- он запускается быстрее всех других PDF-смотрелок, это удобно при использовании из командной строки;
- он умеет принудительно перезагружать документ (клавиша
R).
Вот ещё несколько менее известных, но полезных при таком использовании
xpdf возможностей:- у
xpdfесть удобные клавишы для быстрого переключения масштаба (Z— чтобы уместить страницу,W— уместить по ширине); - включить полноэкранный режим можно сочетанием
ALT-F; - указать желаемый масштаб можно прямо из командной строки:
илиxpdf -z page myfile.pdfxpdf -z width myfile.pdf - и самое главное, можно открыть документ сразу на нужной странице:
xpdf myfile.pdf номерстраницы
Ярлыки:
командная строка,
latex,
PDF
20081118
Встраиваем субтитры в AVI (hardsubs)
Как сделать субтитры? Очень просто: ставим
В идеале, так их и надо распространять. Отдельным файлом. Однако зрителю придётся озаботится установкой правильных шрифтов, указать правильную кодировку субтитров в своём плеере, и вообще, пользоваться плеером, который умеет показывать субтитры.
Можно же встроить субтитры прямо в видео (пережать видео так, чтобы субтитры стали частью видеокартинки). Тогда они будут правильно видны у любого зрителя (в т.ч. на всякию ютубах). Правда, увы, их нельзя будет отключить или как-то изменить.
Чтобы встроить субтитры в видео, вначале подбираем нужные параметры их воспроизведения, например, так:
gaupol, запускаем, выбираем File→New, сохраняем в пустой файл mysubs.srt, подключаем видео (File→Select Video, этот пункт недоступен, пока мы не сохраним проект), после этого аккуратно вписываем все субтитры, иногда нажимая кнопку Play, чтобы посмотреть на результат и заметить время. Спустя некоторое время у нас окажется готовый файл с субтитрами mysubs.srt.В идеале, так их и надо распространять. Отдельным файлом. Однако зрителю придётся озаботится установкой правильных шрифтов, указать правильную кодировку субтитров в своём плеере, и вообще, пользоваться плеером, который умеет показывать субтитры.
Можно же встроить субтитры прямо в видео (пережать видео так, чтобы субтитры стали частью видеокартинки). Тогда они будут правильно видны у любого зрителя (в т.ч. на всякию ютубах). Правда, увы, их нельзя будет отключить или как-то изменить.
Чтобы встроить субтитры в видео, вначале подбираем нужные параметры их воспроизведения, например, так:
$ mplayer -subwidth 75 -subcp utf8 -subfont-text-scale 3 -sub mysubs.srt myvideo.aviman mplayer. После этого перекодируем видеофайл:$ mencoder -oac mp3lame -ovc lavc -lavcopts vcodec=mpeg4:vbitrate=2000 myvideo.avi -subwidth 75 -subcp utf8 -subfont-text-scale 3 -sub mysubs.srt -o myvideo-with-hardsubs.avi
Ярлыки:
видео,
командная строка
До стабильного релиза Debian осталось…
Помню, как накануне выхода Intrepid Ibex весь инет пестрел картинками: осталось столько-то дней. Но мы-то ждём безглючного Lenny! А он будет готов тогда, когда будет готов, т.е. когда будут закрыты все баги. Итак, веселья ради, мой счётчик*:
Вставляется так:
Пример здесь: Debian RC-bugs countdown
Кстати, говорят, уже первый релиз-кандидат инсталлятора вышел…
* В RSS-аггрегаторах может не показываться, вставляется IFRAME-ом.
Дополнение: вышел, вышел уже родимый Lenny. Просто праздник!
Вставляется так:
Пример здесь: Debian RC-bugs countdown
Кстати, говорят, уже первый релиз-кандидат инсталлятора вышел…
* В RSS-аггрегаторах может не показываться, вставляется IFRAME-ом.
Дополнение: вышел, вышел уже родимый Lenny. Просто праздник!
Ярлыки:
debian
20081114
Статья: Как сделать GNU/Linux популярным
Интересная статья «Как сделать популярный дистрибутив». Основной тезис, что дело не в программном обеспечении или тех или иных свойствах дистрибутива, а в доступности коммерческих (т.е. доступных любому) услуг по установке и настройке GNU/Linux для конечного пользователя. Мне тезис кажется правильным.
Думаю, многие бы пользователи с радостью бы воспользовались такой услугой, ведь при этом за фиксированную плату они получат надёжный компьютер для интернета, редактирования документов, фото, просмотра видео и т.д., и смогут забыть про вирусы. А барьер по переходу от свежеустановленного дистрибутива (любого) до такой настроенной и работающей как надо пользователю системы обычно как раз и есть та причина, по которой простому человеку линукс я никогда не рекомендую. После же преодоления таких препятствий, как правило, система может использоваться очень долго практически без поддержки (так большинство пользователей и поступает).
Думаю, многие бы пользователи с радостью бы воспользовались такой услугой, ведь при этом за фиксированную плату они получат надёжный компьютер для интернета, редактирования документов, фото, просмотра видео и т.д., и смогут забыть про вирусы. А барьер по переходу от свежеустановленного дистрибутива (любого) до такой настроенной и работающей как надо пользователю системы обычно как раз и есть та причина, по которой простому человеку линукс я никогда не рекомендую. После же преодоления таких препятствий, как правило, система может использоваться очень долго практически без поддержки (так большинство пользователей и поступает).
Ярлыки:
ссылки
20081112
Удалённое журналирование домашнего маршрутизатора
Матёрые сисадмины (я себя к ним не отношу) это и так знают, но простым пользователям это тоже может быть полезно. Бывает, что с домашней точкой доступа/маршрутизатором/DSL-модемом что-то случается и надо разобраться. Доступ к таким устройствам обычно только через веб-интерфейс. И даже если там включено журналирование, читать их журнал событий («лог») через веб-интерфейс не всегда удобно, да и время его хранения там не регулируется. К счастью, его можно перенаправить на нормальную GNU/Linux машину и сохранить в общем системном журнале.
Последовательность действий.
1. Включаем удалённое журналирование на маршрутизаторе. На моём Linksys-е, например, в веб-интерфейсе я выбираю Administration/Reporting/Syslog IP Address. Вводим IP-адрес своей машины. Чтобы узнать адрес своей машины:
Понятное дело, что IP-адрес машины, сохраняющий журнал, предпочтителен статический, иначе придётся менять настройку каждый раз, когда меняется адрес.
2. На локальной машине, где будет писаться лог, требуем от syslog-а принимать логи от удалённых машин. Эта возможность по-умолчанию выключена, включается опцией -r при запуске сервера. В Debian-системах редактируем файл /etc/default/syslogd, и добавляем опцию в переменную SYSLOGD:
2б. Для удобства, можно прописать IP-адрес маршрутизатора в файл /etc/hosts, что-нибудь вроде
тогда в логах записи полученные с него записи будут помечаться именем «коробочки», а не её IP-адресом.
3. Перезапускаем syslogd:
4. Журнал маршрутизатора теперь будет добавляться в /var/log/messages:
Последовательность действий.
1. Включаем удалённое журналирование на маршрутизаторе. На моём Linksys-е, например, в веб-интерфейсе я выбираю Administration/Reporting/Syslog IP Address. Вводим IP-адрес своей машины. Чтобы узнать адрес своей машины:
$ ip addr | grep 'inet\>'
Понятное дело, что IP-адрес машины, сохраняющий журнал, предпочтителен статический, иначе придётся менять настройку каждый раз, когда меняется адрес.
2. На локальной машине, где будет писаться лог, требуем от syslog-а принимать логи от удалённых машин. Эта возможность по-умолчанию выключена, включается опцией -r при запуске сервера. В Debian-системах редактируем файл /etc/default/syslogd, и добавляем опцию в переменную SYSLOGD:
SYSLOGD="-r"
2б. Для удобства, можно прописать IP-адрес маршрутизатора в файл /etc/hosts, что-нибудь вроде
192.168.1.1 router
тогда в логах записи полученные с него записи будут помечаться именем «коробочки», а не её IP-адресом.
3. Перезапускаем syslogd:
$ sudo invoke-rc.d sysklogd restart
4. Журнал маршрутизатора теперь будет добавляться в /var/log/messages:
$ tail -f /var/log/messages | grep router
Nov 12 11:22:31 router secondary DNS address 193.70.152.25
Nov 12 11:22:31 router run_program(/etc/ppp/ip-up)
…
20081111
Python на службе науки (черновик)
Не знаю, соберусь ли это дело систематизировать, пока буду просто добавлять в этот пост короткие «рецепты» по применению Python в околонаучных целях (создание отчётов, построение графиков и тому подобное). Поживём-увидим.
Преобразование числа из экспоненциальной формы (например, –1.2e+003) в формулу LaTeX (например, -1.2 10³). Регулярное выражение:
Прозрачные/полупрозрачные легенды (подписи) в графиках
Формулы LaTeX в подписях и надписях в
Открытый вопрос — как делать русские подписи в Дополнение: вопрос решился сам. См. заметку Русские буквы в matplotlib/pylab.
Произвольная надпись, выровненная по центру —
Дана пара массивов (списков)
Из полученных пар выделить опять отдельные массивы
Кусочно-линейная интерполяция зависимости
Транспонирование двумерного массива — проще всего
Линейная регрессия (аналогично — фиттирование более сложных функций, модифицировать количество параметров и вычисление ошибки в
Интегрирование системы обыкновенных дифференциальных уравнений (ОДУ):
Чтобы построить график полученного решения (2D), транспонируем
Преобразование числа из экспоненциальной формы (например, –1.2e+003) в формулу LaTeX (например, -1.2 10³). Регулярное выражение:
>>> import re
>>> re.sub('([\d.+-]+)[Ee]\+?([-]?)0*([\d]+)', '\\1 \\cdot 10^{\\2\\3} ','-1.2e+003')
'-1.2 \\cdot 10^{3} '
Прозрачные/полупрозрачные легенды (подписи) в графиках
pylab:l=legend()
l.get_frame().set_alpha(0.2)
Формулы LaTeX в подписях и надписях в
pylab: просто заключить нужный фрагмент надписи в $…$, например '$\rho$'.pylab?Произвольная надпись, выровненная по центру —
(xlim()[0]+xlim()[1])*0.5, ha="center" — нижнего края — lim()[0], va="bottom") — графика в pylab:text((xlim()[0]+xlim()[1])*0.5,ylim()[0],"your message",ha="center",va="bottom",fontsize=10)
Дана пара массивов (списков)
t и x с временем измерения и измеренной величиной, отобрать только те пары время-значение, которые попадают в заданный временной интервал [t0, t1] (или какому другому условию):xt=[ pair for pair in zip(x,t) if t0 <= pair[0] <= t1 ]
Из полученных пар выделить опять отдельные массивы
t и x:t=[pair[0] for pair in tx]или с использованием
x=[pair[1] for pair in tx]
array из scipy:t,x=array(tx)[:,0],array(tx)[:,1]
Кусочно-линейная интерполяция зависимости
t→x на другом наборе точек t2 (тоже список, как и t):from scipy import interp
interp(t2,t,x)
Транспонирование двумерного массива — проще всего
array([[1,2,],[3,4]]).transpose().Линейная регрессия (аналогично — фиттирование более сложных функций, модифицировать количество параметров и вычисление ошибки в
residual()). Как и прежде, предполагаю, что точки для фиттирования заданы в массивах t и x:from scipy import array
from scipy.optimize import leastsq
def residual(params,t,x):
a,b=params
x_ab=array([a*x=t_i+b for t_i in t])
return x_ab-x
[a,b],ier=leastsq(residual,(1,1),args=(t,x))
Интегрирование системы обыкновенных дифференциальных уравнений (ОДУ):
from scipy import linspace, array
from scipy.integrate import odeint
def dotu(u,t0):
"расчёт производных в момент времени t0"
x,y,z=u # вектор переменных
sigma,rho,beta=10,28,8.0/3 # параметры модели
dotx=sigma*(y-x)
doty=x*(rho-z)-y
dotz=x*y-beta*z
return [dotx,doty,dotz]
t=linspace(0,50,1e4) # точки интегрирования
u0=[-5,-5,1] # начальное условие
u=odeint(dotu,u0,t) # решение
Чтобы построить график полученного решения (2D), транспонируем
u и строим как обычно:from pylab import plot, show
u=array(u).transpose()
plot(u[1],u[2]) # строим фазовый портрет y-z
show()
20081107
Приёмы работы в коммандной строке *NIX
По мотивам дискуссии на слэшдоте. Всякие полезные, занятные и совсем бесполезные мелочи, позволяющие сделать работу в коммандной строке удобнее и приятнее. Кое-что добавил уже от себя. Многим это, конечно, и так известно, но коллективный опыт всегда больше. Я для себя кое-что почерпнул.
- Началось с упоминания о
write, которая позволяет слать сообщения другим пользователям системы.
Хотя, если права позволяют, можно просто писать$ w
…
sergey pts/1 :0.0 11:34 3.00s 0.18s 0.18s bash
$ write sergey pts/1
hi there!
^D$ echo '^LAll files deleted.' > /dev/pts/1 TAB-TAB-TAB:-)
- Не обошлось без шуток. Мне понравился «коан»:
И «про уток»:$ grep '' /dev/null$ du -cks - А
screenпозволяет подключаться и отключаться к виртуальному терминалу, который работает даже если выйти из системы, имеет кучу применений, от запуска «долгоиграющих» процессов на удалённых машинах до экстремального программирования; также очень полезен для создания «общего» терминала (screen -x), можно видеть, что делает другой человек, или показывать ему то, что делаешь. На удалённой машине обычно запускаю так:
Список виртуальных терминалов:$ screen -RD^Aw. Выбор терминала:^Aцифра. Отсоединися отscreen-а (не закрывая его терминалы):^Ad
cd -, чтобы вернуться в предыдущий каталог (доcd) иcd `pwd -P`, чтобы перейти по настоящему пути (если пришёл по символической ссылке). Ещё полезныpushdиpopd(запомнить текущий каталог и потом в него вернуться).
history | grep шаблон, чтобы вспомнить, что уже делал.^Rфрагмент-команды^R^R^R…, чтобы найти и повторить ранее выполненную команду.^Nи^Pчтобы прокручивать историюbashвперёд и назад.
- Чтобы повторить последнюю команду:
И при редактировании команды —$ !!ESC., чтобы подставить последний аргумент последней команды. В эту же категорию попадает ещё целая пачка трюков (man bash,/^HISTORY EXPANSION).
- Если в режиме поиска команды нажать
^O, то будет исполнена текущая команда из истории и после этого будет набрана следующая команда из истории. Можно автоматизировать весь цикл редактирование-компиляция-исполнение. Проще объяснить на примере:$ vi foo.c
$ gcc -o foo{,.c}
$ ./foo
$ ^Rvi^O^O^O^O^O… - Для любителей
viможно переключить сочетания клавиш
после этого ESC чтобы перейти в коммандный режим и режима вставки,$ set -o vik/j, чтобы прокручивать историю команд,/шаблонENTER, иn/N, чтобы искать по истории. Если честно, хотя и и пользуюсь постоянноvim, вbashпо-умолчанию всё равно Emacs-овские сочетания…
META-tвbash, чтобы поменять местами аргументы.
^Sи^Q, чтобы приостановить и продолжить вывод в терминал («пауза»).
resetобычно приходится набирать вслепую (после неудачного вывода бинарного файла в stdout). Чаще достаточно^L.
sshи много-много-много его применений.-XCдля запуска иксовых приложений на удалённой машине с локальным X-сервером.-D,-Lи-Rдля создания защищённых тунелей. Требует отдельного обсуждения.
sftp, имитация FTP-клиента поверх SSH, иsshfsдля подключения удалённой файловой системы поверх SSH (я бы добавил сюдаscpиrsync).
wc -l, чтобы подсчитать количество строк.nl, чтобы добавить номера строк.
sortдля сортировки строк.sort -n— числовая сортировка.
… | rev | sort | rev, чтобы сгруппировать строки по окончаниям.
du -sh * | sort -nнеплохая замена графическомуbaobab(точнее наоборот).
head -количествострокиtail -количествострокдля печати начала и конца файла,tail -f, чтобы следить за файлом, который ещё пишется (например, лог). Полезный вариант:tail -F возможно-несуществующий-файл.
strings, чтобы увидеть человеко-читаемые строки, встречающиеся в файле. См. пример в предыдущем посте.
grep, чтобы отобрать только нужные строчки,… | grep шаблон. Мне часто полезны опции-r(рекурсивно во вложенных подкаталогах) и-i(без учёта регистра). Да,grepподдерживает также опцию--color(нагляднее).
awkдля того, чтобы разбить строчку на поля и вытащить только нужные.… | awk -F'разделитель' '{print $номер-поля;}'
В простых случая можно использовать$ echo "a,b,c" | awk -F',' '{print $2;}'cut -d 'разделитель' -f список-полей:$ echo 'a,b,c' | cut -d ',' -f 2- Обратные апострофы (
`команда`или$(команда)) подставляют результат выполнения команды.$ NOW=$(date -u)
…
$ echo $NOW
Птн Ноя 7 12:17:07 UTC 2008 - Выполение задания в назначенное время (один раз):
Говорящий будильник:$ echo 'команда' | at время
Такой вот одноразовый$ echo 'for i in `seq 1 10`; do echo wake up, internet was updated | festival --tts ; done;' | at 08:00cron.
findочень стоит того, чтобы научиться ей пользоваться. Особенно полезна опция-exec команда, в которой {} заменяет имя найденного файла \;. Для меня стало открытием, что-execможно использовать также в качестве условия для выбора файлов:$ find . -exec grep -q 'шаблон' {} \; -printecho *вместоls.ls -vдля «правильной» сортировки пронумерованных файлов (12.txt после 2.txt).ls -tgoпокажет недавно изменённые файлы первыми.
- Мне очень нравятся фигурные скобки в
bash. Так можно писать:
вместо$ gcc -o foo{,.c}
$ convert /длинный/путь/к/image.{eps,jpg}$ gcc -o foo foo.c
$ convert /длинный/путь/к/image.eps /длинный/путь/к/image.jpg - Управление процессами:
^Z,bg,fg,jobs,kill %номерзадачи. И тогдаpsнужен гораздо реже. Аhtop, кстати, удобнее, чем простоtop.
- Раскрытие переменных в
bash:${var%ending-to-remove}newending,${var/find/replace},${var//find/replace-all},${var#prefix-to-remove}.
- Циклы в
bash:for f in * ; do команды ; doneчтобы обработать все файлы (*),for i in `seq 1 10` ; do команды ; doneчтобы перебрать всеiот 1 до 10. В скриптах удобно использовать неявные циклы видаwhile [ $# -gt 0 ] ; do arg=$1; shift; … ; done.
- Широко известно про
ddдля создания образов дисков, их бэкапа и восстановления.
Менее известный приём:# dd if=/dev/раздел of=/media/backup/образ-раздела bs=1k conv=noerror,synckillall -USR1 dd, чтобы увидеть, сколько уже сделано.
lsof /media/том, чтобы узнать, какой процесс использует файлы на нежелающем отсоединяться диске. Может пригодится и для решения проблем с файлами устройств (/dev/что-нибудь).
Другой вариант —fuser -v /media/том. Тоже очень удобно.
eject, чтобы выдвинуть подставку для кофе.
cal 11 2008и мы вспоминаем, что сегодня пятница.dateи узнаём, который час.
- Из всевозможных «калькуляторов» под рукой почти всегда будет вот этот:
Ещё традиционный вариант для интерактивного использования —$ awk 'BEGIN{ print exp(1)+2^(1.0/3); }'bc -l. В нём, правда, нестандартные названия функций:s(x)— синус,c(x)— косинус,a(x)— арктангенс,l(x)— натуральный логарифм,e(x)— экспонента,x^n— целая степень. Предыдущее выражение можно посчитать так:
А целые числа умеет складывать и$ bc -l
...
e(1)+e((1/3)*l(2))
3.97820287835391840011bash:echo $((2+2)).
time командачтобы засечь время выполнения задачи.
ulimit -m размер-памяти-в-килобайтахограничить максимальный размер памяти процессов, вызываемых из текущей оболочки. Вариант:-v размер-памяти-в-килобайтахдля ограничения размера виртуальной памяти. Полезно, если есть опасения, что процесс слишком жадный.
nice -n +10 командавыполнить команду с пониженным на 10 приоритетом. Полезно, если команда работает долго, требует много процессорного времени, а оно нужно и для другого.
- Доб. 2008-11-26: чтобы после поиска по истории вернуться к последним коммандам,
ESC >.
cut, bc -l и fuser.
Ярлыки:
командная строка
20081106
Удаление потайных ID3 тегов вроде www.mp3-ogg.ru
Столкнулся с тем, что в mp3 бывают скрытые «неудаляемые» теги. В частности, в интернет-обращении находятся файлы, в которых в поле жанр указано «www.mp3-ogg.ru». И сколько бы я ни прописывал правильные теги в EasyTAG, или даже пытался удалять все (ID3v1 и ID3v2) теги из такого файла (в EasyTAG или с помощью
Похоже, это связано с так называемыми APETAGS, будь они неладны. Только старый добрый
Как заметил наблюдательный народ, потайные теги расположены в конце файла. Убедиться в этом можно, например, так:
id3v2 -D file.mp3), при добавлении файла в библиотеку Rhythmbox поганое «www.mp3-ogg.ru» всё равно вылазит.Похоже, это связано с так называемыми APETAGS, будь они неладны. Только старый добрый
mpg321 показывает нормальные ID3v2/ID3v1 теги.Как заметил наблюдательный народ, потайные теги расположены в конце файла. Убедиться в этом можно, например, так:
$ strings test.mp3 | tail -14
APETAGEX
TITLE
ARTIST
ALBUM
YEAR
2007,
COMMENT
GENRE
www.mp3-ogg.ru
COPYRIGHT
Make Love Not War
TRACKNUMBER
1APETAGEX
2007$ tagwipe.py test.mp3
Ярлыки:
звук,
командная строка,
скрипт,
mp3
20081025
Как сшивать панорамы
Давно хотел написать эту заметку. Расскажу о том, как можно сравнительно легко склеивать панорамы из отдельных фотоснимков. Хотя на всех иллюстрациях снимки экрана сделанны в линуксе, все описываемые программы доступны и пользователям других операционных систем (Windows, MacOS X). Так что аудитория этой заметки заметно шире моей обычной аудитории. В отличие от панорамного софта, который чаще всего упоминается в рунете, эти программы свободны и распространяются бесплатно. Итак, герои сегодняшнего дня:
Hugin. Графический интерфейс для склейки панорам. В примерах использовалась версия 0.7.0-beta5. Программа названа в честь одного из воронов Одина.
Autopanosift. Программа ищет «связующие точки» между отдельными кадрами. В большинстве случаев вызывается из Хугина.
Enblend. Бесшовно склеивает отдельные кадры в единое изображение. Она обычно тоже запускается автоматически из Хугина, хотя в сложных случаях её можно запускать и вручную.
Ещё потребуется какой-нибудь графический редактор. В примерах у меня будет показан nip2 (умеющий работать даже с очень большими изображениями) и Gimp. В общем, это дело вкуса.
В общих чертах, технологический процесс выглядит так:
Нужно взять фотокамеру и последовательно снимать фрагменты будущей панорамы. Здесь есть несколько тонкостей:
В результате получаем набор кадров будущей панорамы. Например, такой:

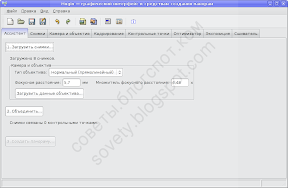
Запускаем Хугин. В современных версиях Хугина все основные действия доступны прямо с его первой вкладки. По порядку, сверху вниз. Вначале загружаем фото:
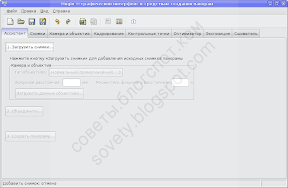
После этого нужно создать контрольные точки. Жмём «Объединить…»:
После этого запустится Autopanosift:
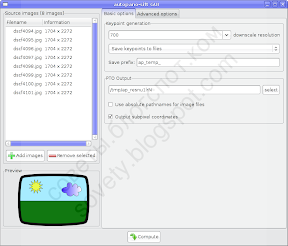
Как правило, достаточно нажать кнопку «Compute» и дождаться, пока программа найдёт все контрольные точки.
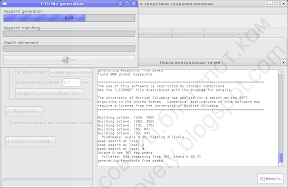
Когда Autopanosift закончит, кнопка «Exit» в его окошке станет доступна:
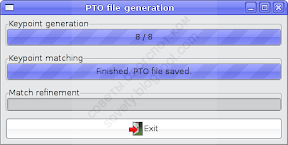
Жмём и попадаем обратно в Хугин. Вначале откроется окно предварительного просмора
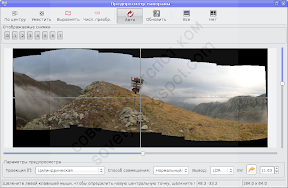
Это результат предварительной сшивки. Чтобы увидеть проблемные области, удобно переключить режим совмещения с нормального на «Разницу», тогда в области перекрытия кадров светлый цвет будет соответствовать несовпадению изображений:
Однако закроем предварительный просмотр и вернёмся на первую вкладку Хугина. Там будут указаны параметры оптимизации. В данном случае предварительный результат оставляет желать лучшего:
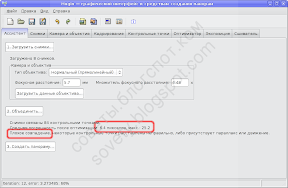
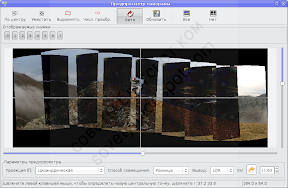
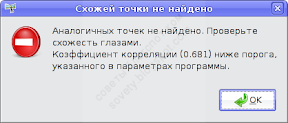
Максимальная погрешность оптимизации составила 25 пикселей, т.е. одна из контрольных точек отстоит от своей пары на соседнем снимке на 25 пикселей. Это действительно плохо.
Перейдём на вкладку «Контрольные точки» и, попарно разглядывая кадры, посмотрим, как их расставил Autopanosift. Вот, например, и наша проблемная точка:
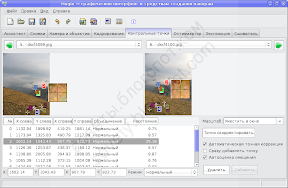
Проблемная точка оказалась где-то в облаках. И это хорошо, это легко исправить. Вообще, следует избегать размещения контрольных точек на изменчивых объектах: облаках, качающейся траве, волнах. Контрольные точки на таких объектах — почти гарантия проблем сшивки.
К сожалению, Autopanosift не умеет распознавать объекты на фото и предсказывать их поведение. Поэтому результаты его работы требуется корректировать вручную. В частности, точки на облаках можно просто убрать.
Другой нюанс. Autopanosift не умеет распознавать линию горизонта или гор, или стену здания, а для зрителя очень важно, чтобы они были ровными, неразрывными. Чтобы это обеспечить, проще всего просто добавить кое-где точки вдоль таких линий, тогда их положение будет учитываться при оптимизации панорамы.
На иллюстрации я добавляю такую точку:
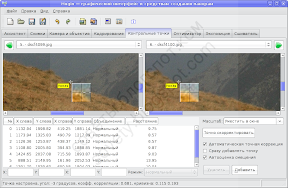
Для этого я щёлкаю на выбранной точке на снимке слева, а затем примерно в том же месте на снимке справа. Чаще всего Хугин правильно размещает парную точку на втором снимке. Иногда же ему это не удаётся, и тогда можно увидеть такое сообщение:
Ничего страшного, парную точку можно уточнить вручную. Современные версии Хугин услужливо увеличивают окрестность точки, так что правильно поставить парную точку легко. Уточнив её положение, нажимаем «Добавить».
Ещё пара советов о расположении точек: избегайте «кучкования» всех контрольных точек в одном месте, особенно если это место находится на переднем плане, небольшие ошибки в положении этих точек будут соответствовать большим смещениям кадра при оптимизации. Старайтесь «выкладывать» контрольные точки вдоль важных для глаза контуров (и наоборот, не ставьте слишком много там, где глаз не чувствует линии).
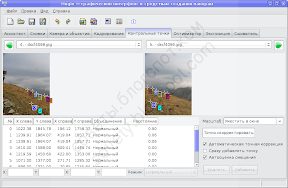
Вот, например, сравните как расставила точки программа:
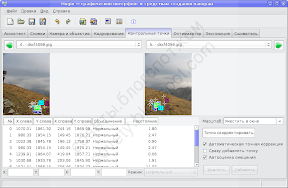
и как лучше их расположить:
Есть ещё один тип контрольных точек, пример которых я не буду приводить, потому что в данной панораме они не понадобились. Если обе точки пары поставить на один и тот же кадр, то зададут горизонталь или вертикаль в этом кадре. Это полезно, если в кадре есть архитектурные сооружения или деревья. Один известный дизайнер много писал о том, что здания на фотографиях должны стоять вертикально.
Поправив контрольные точки, попробуем ещё раз оптимизировать панораму. Кстати, если перейти на вкладку «Оптимизатор», то можно будет выбрать, какие именно параметры кадра оптимизировать. Мне кажется, что очень часто лучших результатов можно достичь, если оптимизировать не только положение кадра, но и его поворот вокруг оптической оси, «(y,p,r)». Особенно это верно для панорам, снятых с рук (снимая с рук, легко нечаянно немного наклонить камеру).
Заново оптимизировав, можно ещё раз посмотреть на результат в области предварительного просмотра:
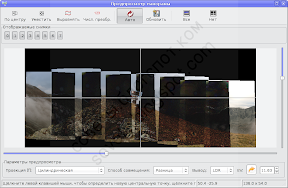
Кстати, в области предварительного просмотра можно посмотреть панораму в разных проекциях, выбрать положение оптической оси виртуального объектива (щелчок левой кнопкой мыши по области изображения) или повернуть виртуальный объектив вокруг оптической оси (щелчками правой кнопки мыши по области изображения).
Очень полезны функции «По центру» и «Уместить», а вот функцией «Выровнять» надо пользоваться осторожно. Если панорама была снята с горизонтально выровненного штатива, то выравнивание вообще не должно требоваться, если же сняли с рук, и кадры пошли «волной», то иногда выравнивание помогает убрать волну, но мне кажется, что при этом ухудшается результат сшивки. Функция «Выровнять» в Хугине довольно новая.
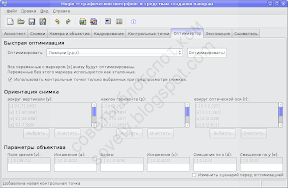
Теперь, если всё в порядке, делаем последний шаг. Переходим на вкладку «Сшиватель», выбираем проекцию, советую ещё раз рассчитать поле зрения и выбрать оптимальный размер (при котором не происходит уменьшения изображения).
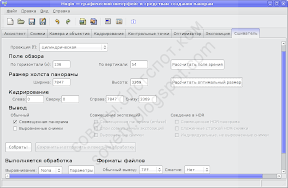
Для просмотра на экране целиком, на мой взгляд, очень хорошо подходит цилиндрическая проекция. Если же планируется просматривать в тех или иных программах просмотра, например в апплете PTViewer, то лучше использовать эквидистантную проекцию (или ту, которую требует программа просмотра). А «рыбий глаз», по-моему, лучше всё равно снимать «рыбьим глазом».
Результат сшивки я всегда сохраняю в формате TIFF, потому что потом его ещё приходится редактировать. Жмём «Собрать», и ждём:
Ждём долго, это, пожалуй, самый долгий вычислительный процесс во всей технологической цепочке. Конец этого процесса выглядит примерно так:
Всё. У нас теперь есть большой файл со сшитой панорамой. Сохраняем проект Хугина и закрываем. Дальше нужно довести сшитую панораму до ума.
Итак, у нас теперь есть TIFF-файл со сшитой панорамой. Он может быть довольно большим. В этом примере он получился 101 мегабайт. В действительно больших панорамах счёт может пойти на гигабайты. Поэтому я приведу пример, как можно обрезать панораму в редакторе nip2, который может работать даже с изображениями, размер которых превышает размер оперативной памяти.
Вообще, редактор nip2 довольно нетрадиционный. Советую для первого знакомства посмотреть заметку о нём Михаила Конника. Редактор по принципу работы больше похож на электронные таблицы, но работает действительно быстро.
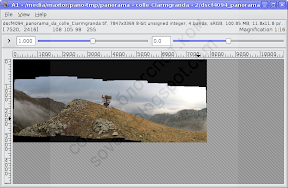
Чтобы обрезать нашу панораму, дважды щёлкнем по ячейке с исходным файлом A1. Откроется новое окно с изображением:
Масштабируем с помощью Ctrl+колёсико мышки. Зажав Ctrl и перетягивая мышку от левого верхнего угла к правому нижнему выделяем прямоугольную область:
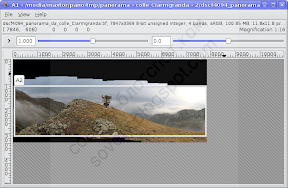
Да, выделять прямоугольную область в nip2 нужно именно так: от верхнего левого угла к правому нижнему и зажав Ctrl.
Теперь в главном окне nip2 появляется новая ячейка A2:
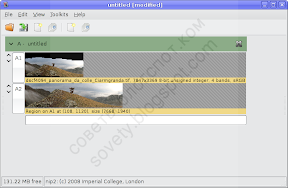
Именно содержимое этой ячейки (уже обрезанную панорамe) мы и сохраняем в файл.
В данном случае я обрезал с небольшим запасом, поэтому в одном месте на краю панорамы есть дырка:
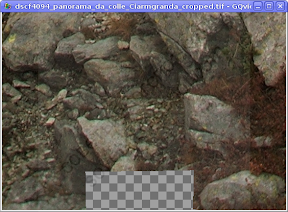
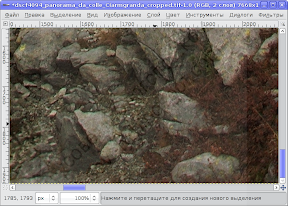
По-моему, лучше оставить такую дырку в малозначительном месте, чем отрезать что-то важное в другом месте панорамы. А в малозначительном месте можно помахать клонирующей кистью:
Наконец, сохраняем окончательный вариант панорамы, добавляем геотаги, и любуемся:

Чтобы добавить геотаги потребуется скопировать EXIF-теги из исходных кадров в окончательный вариант панорамы. Я это делают так:
Одно из самых интересных панорамных сообществ, на мой взгляд, группа Perfect Panoramas на фликере. Туда принимают только те панорамы, в которых модераторы не найдут дефектов.
Есть фотосообщество в ЖЖ, тоже посвященное панорамам. Не помню, как называется.
Панорамам с геотегами — самое место на Panoramio. Хорошие панорамы потом покажут в Google Earth :)
В интернете панорамы можно показывать с помощью апплета PTViewer.
Дополнение 2010-02: со времени написания заметки появился хороший панорамный хостинг pan0.net. На него можно выкладывать как круговые, так и частичные панорамы. Есть флэш-просмотрщик, который можно легко вставлять в блоги.
Перфекционисты и любители монументального искусства могут снимать гигапиксельные панорамы.
Ну и в общем ещё много разных применений этой техники. В том числе и вполне серьёзных.
Успехов!
PS. Я нашёл ещё два сходных руководства на русском языке: Клеим панораму Александра Прокудина и Склейка панорам в Hugin (© БэЖэ). Много учебных материалов доступно на сайте программы Hugin, но, увы, только на английском языке.
Hugin. Графический интерфейс для склейки панорам. В примерах использовалась версия 0.7.0-beta5. Программа названа в честь одного из воронов Одина.
Autopanosift. Программа ищет «связующие точки» между отдельными кадрами. В большинстве случаев вызывается из Хугина.
Enblend. Бесшовно склеивает отдельные кадры в единое изображение. Она обычно тоже запускается автоматически из Хугина, хотя в сложных случаях её можно запускать и вручную.
Ещё потребуется какой-нибудь графический редактор. В примерах у меня будет показан nip2 (умеющий работать даже с очень большими изображениями) и Gimp. В общем, это дело вкуса.
В общих чертах, технологический процесс выглядит так:
- снимаем фото,
- загружаем отдельные кадры в Хугин,
- ищем «связующие точки» между отдельными кадрами, или автоматически (с помощью Autopanosift), или вручную,
- оптимизируем панораму (после этого отдельные кадры располагаются так, чтобы связующие точки по возможности совпадали), смотрим на предварительный результат,
- окончательно выбираем проекцию и склеиваем кадры в единую панораму (на этом этапе пригождается Enblend),
- обрезаем сшитую панораму, проверяем на наличие ошибок сшивки,
- окончательно ретушируем кадр, как в случае обычных фото.
Как снимать панорамы
Нужно взять фотокамеру и последовательно снимать фрагменты будущей панорамы. Здесь есть несколько тонкостей:
- кадры должны перекрываться примерно на треть, это необходимо для успешного поиска связующих точек между отдельными кадрами,
- составлять горизонтальные панорамы удобнее из вертикальных кадров, таким образом вертикальный угол зрения однорядной панорамы будет шире, панорама будет восприниматься естественнее при просмотре целиком на экране компьютера, больше будет запас для окончательного кадрирования,
- чаще всего удобно снимать с широким углом изображения (на минимальном «зуме»), в этом случае панорама будет состоять из минимального числа кадров (и наоборот, когда цель состоит в создании максимально детальной панорамы, стоит снимать длиннофокусным объективом, но в несколько «рядов»),
- используйте бленду или прикрывайте объектив рукой, чтобы избежать бликов на объективе (при съёмке панорам часто приходится снимать почти против света),
- не используйте поляризатор, хотя он и делает цвета сочнее на отдельных кадрах, из-за него небо на панораме в целом выглядит неестестсвенно,
- снимайте все кадры панорамы с одними и теми же настройками экспозиции и баланса белого; хотя Хугин и Enblend и умеют выравнивать экспозицию и баланс белого в итоговой панораме, это не всегда получается достаточно хорошо, а разные цветовые тона сразу делают заметными отдельные кадры в панораме; тут очень может пригодится ручной режим экспозиции в фотокамере (если такой есть),
- то же относится и к фокусному расстоянию, сшивать будет проще, если все кадры будут сняты с одним и тем же фокусным расстоянием,
- старайтесь снимать с горизонтально выровненного штатива, если есть такая возможность; конечно, можно успешно снять панораму и с рук, но очень многие панорамы мне не удались именно из-за того, что я поленился достать штатив,
- как в случае штатива, так и в случае съёмки с рук, важно обеспечить неподвижность оси вращения камеры, в идеале она должна проходить через оптическую ось объектива; особенно хорошо, если ось пройдёт через «точку без параллакса» (вот тут о её поиске по-английски),
- последние два правила особенно важны, если объекты переднего плана расположены близко к камере,
- лучше снимать все кадры последовательно в одном направлении, или слева направо, или справа налево, это минимизирует смещение подвижных объектов (например, облаков) в соседних кадрах; если в панораму попадает какой-то быстродвижущийся объект (например, машина, животное, человек), то потом бывает удобно иметь любой кадр панорамы в двух вариантах, с объектом и без него.
В результате получаем набор кадров будущей панорамы. Например, такой:

Как склеивать кадры в Hugin
Запускаем Хугин. В современных версиях Хугина все основные действия доступны прямо с его первой вкладки. По порядку, сверху вниз. Вначале загружаем фото:
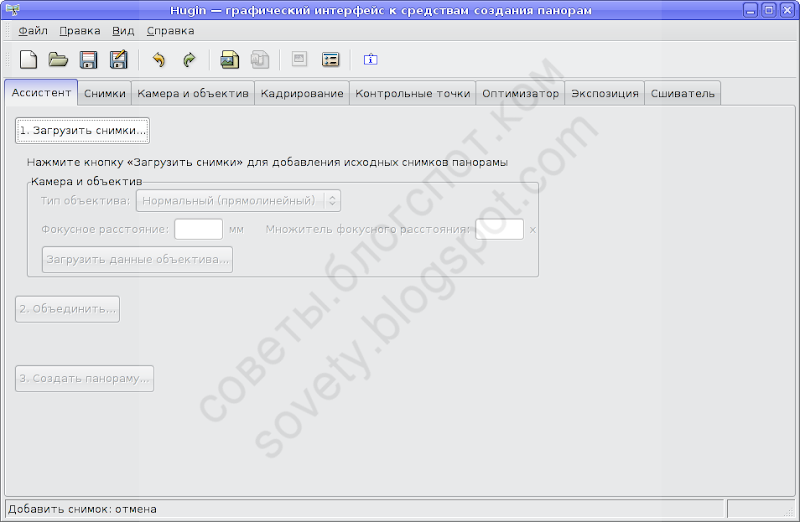
После этого нужно создать контрольные точки. Жмём «Объединить…»:
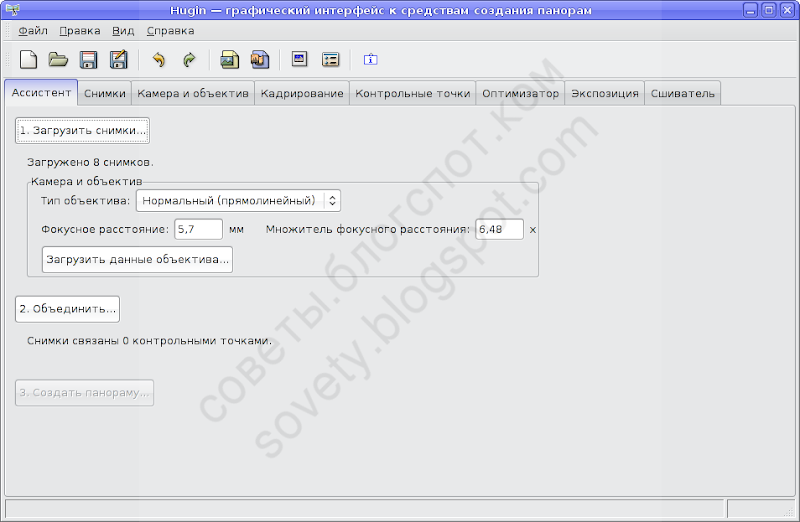
После этого запустится Autopanosift:

Как правило, достаточно нажать кнопку «Compute» и дождаться, пока программа найдёт все контрольные точки.
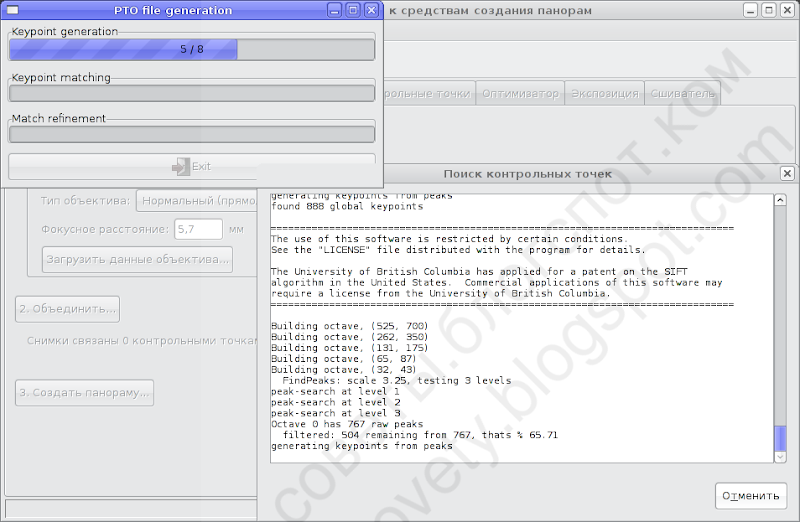
Когда Autopanosift закончит, кнопка «Exit» в его окошке станет доступна:
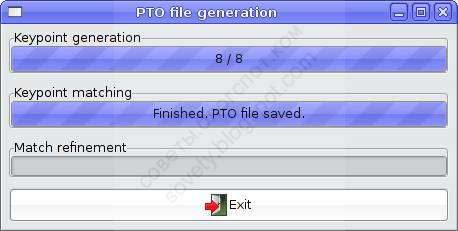
Жмём и попадаем обратно в Хугин. Вначале откроется окно предварительного просмора
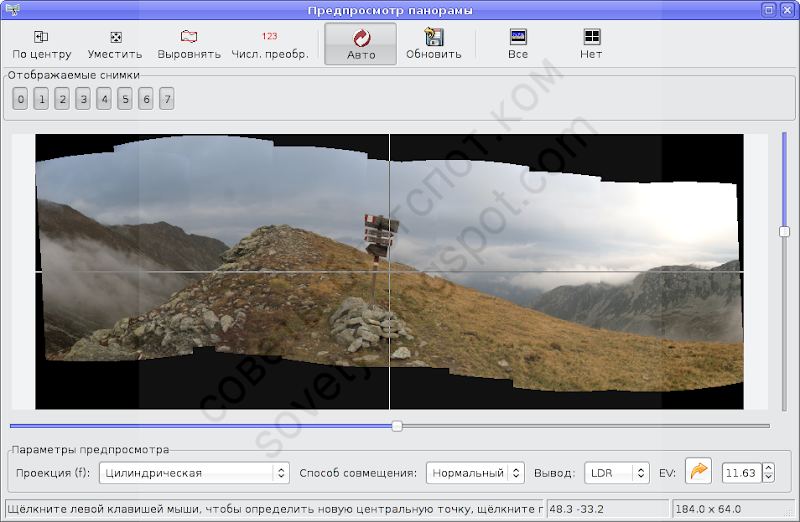
Это результат предварительной сшивки. Чтобы увидеть проблемные области, удобно переключить режим совмещения с нормального на «Разницу», тогда в области перекрытия кадров светлый цвет будет соответствовать несовпадению изображений:

Однако закроем предварительный просмотр и вернёмся на первую вкладку Хугина. Там будут указаны параметры оптимизации. В данном случае предварительный результат оставляет желать лучшего:
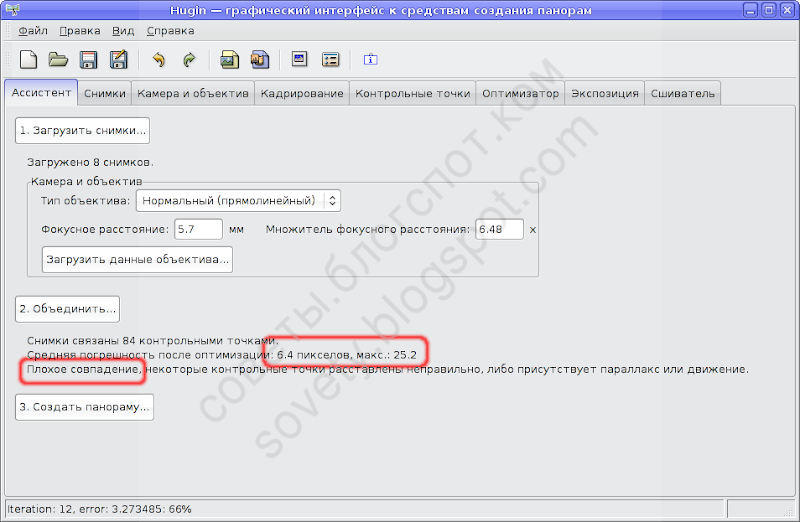
Максимальная погрешность оптимизации составила 25 пикселей, т.е. одна из контрольных точек отстоит от своей пары на соседнем снимке на 25 пикселей. Это действительно плохо.
Перейдём на вкладку «Контрольные точки» и, попарно разглядывая кадры, посмотрим, как их расставил Autopanosift. Вот, например, и наша проблемная точка:
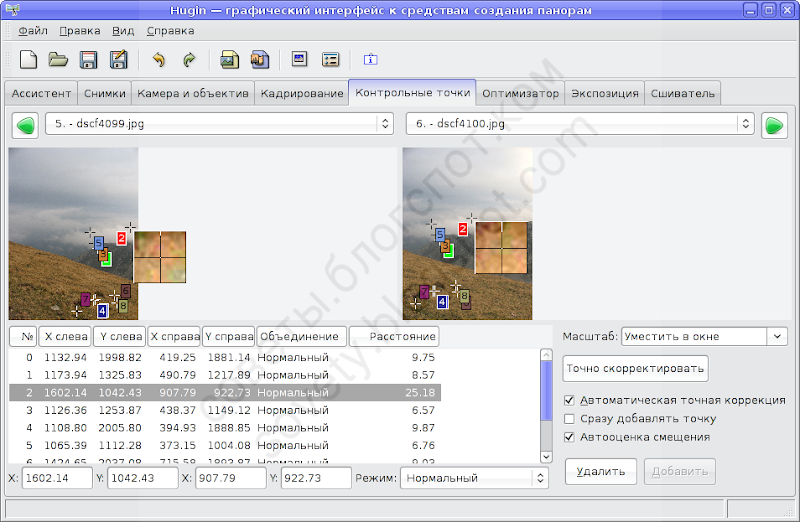
Проблемная точка оказалась где-то в облаках. И это хорошо, это легко исправить. Вообще, следует избегать размещения контрольных точек на изменчивых объектах: облаках, качающейся траве, волнах. Контрольные точки на таких объектах — почти гарантия проблем сшивки.
К сожалению, Autopanosift не умеет распознавать объекты на фото и предсказывать их поведение. Поэтому результаты его работы требуется корректировать вручную. В частности, точки на облаках можно просто убрать.
Другой нюанс. Autopanosift не умеет распознавать линию горизонта или гор, или стену здания, а для зрителя очень важно, чтобы они были ровными, неразрывными. Чтобы это обеспечить, проще всего просто добавить кое-где точки вдоль таких линий, тогда их положение будет учитываться при оптимизации панорамы.
На иллюстрации я добавляю такую точку:
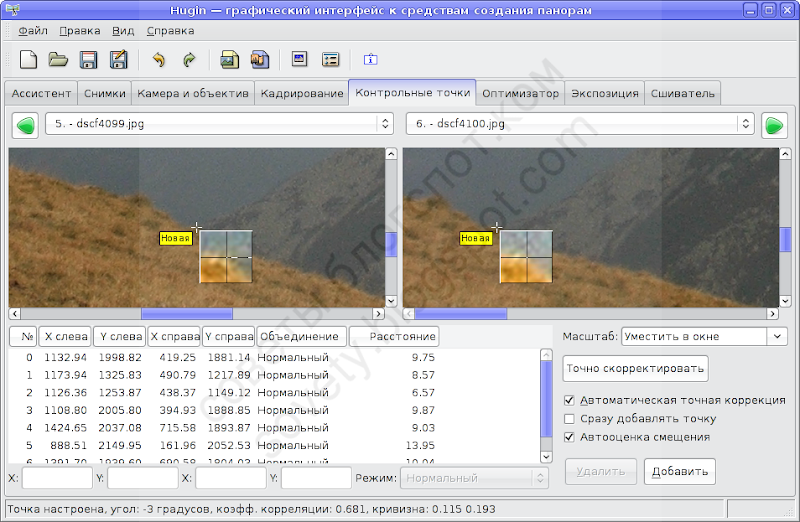
Для этого я щёлкаю на выбранной точке на снимке слева, а затем примерно в том же месте на снимке справа. Чаще всего Хугин правильно размещает парную точку на втором снимке. Иногда же ему это не удаётся, и тогда можно увидеть такое сообщение:

Ничего страшного, парную точку можно уточнить вручную. Современные версии Хугин услужливо увеличивают окрестность точки, так что правильно поставить парную точку легко. Уточнив её положение, нажимаем «Добавить».
Ещё пара советов о расположении точек: избегайте «кучкования» всех контрольных точек в одном месте, особенно если это место находится на переднем плане, небольшие ошибки в положении этих точек будут соответствовать большим смещениям кадра при оптимизации. Старайтесь «выкладывать» контрольные точки вдоль важных для глаза контуров (и наоборот, не ставьте слишком много там, где глаз не чувствует линии).
Вот, например, сравните как расставила точки программа:
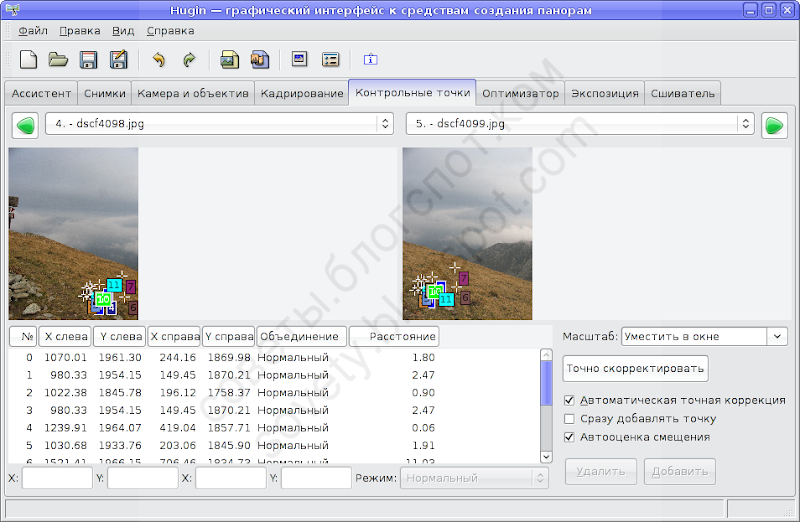
и как лучше их расположить:
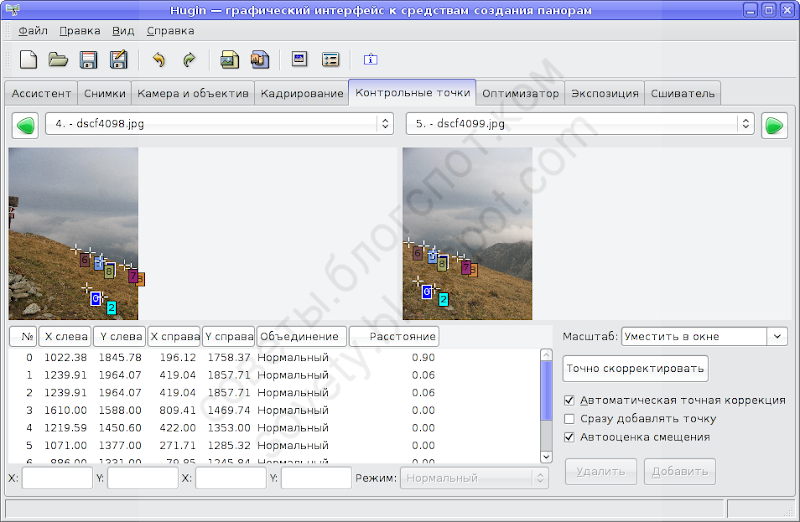
Есть ещё один тип контрольных точек, пример которых я не буду приводить, потому что в данной панораме они не понадобились. Если обе точки пары поставить на один и тот же кадр, то зададут горизонталь или вертикаль в этом кадре. Это полезно, если в кадре есть архитектурные сооружения или деревья. Один известный дизайнер много писал о том, что здания на фотографиях должны стоять вертикально.
Поправив контрольные точки, попробуем ещё раз оптимизировать панораму. Кстати, если перейти на вкладку «Оптимизатор», то можно будет выбрать, какие именно параметры кадра оптимизировать. Мне кажется, что очень часто лучших результатов можно достичь, если оптимизировать не только положение кадра, но и его поворот вокруг оптической оси, «(y,p,r)». Особенно это верно для панорам, снятых с рук (снимая с рук, легко нечаянно немного наклонить камеру).

Заново оптимизировав, можно ещё раз посмотреть на результат в области предварительного просмотра:

Кстати, в области предварительного просмотра можно посмотреть панораму в разных проекциях, выбрать положение оптической оси виртуального объектива (щелчок левой кнопкой мыши по области изображения) или повернуть виртуальный объектив вокруг оптической оси (щелчками правой кнопки мыши по области изображения).
Очень полезны функции «По центру» и «Уместить», а вот функцией «Выровнять» надо пользоваться осторожно. Если панорама была снята с горизонтально выровненного штатива, то выравнивание вообще не должно требоваться, если же сняли с рук, и кадры пошли «волной», то иногда выравнивание помогает убрать волну, но мне кажется, что при этом ухудшается результат сшивки. Функция «Выровнять» в Хугине довольно новая.
Теперь, если всё в порядке, делаем последний шаг. Переходим на вкладку «Сшиватель», выбираем проекцию, советую ещё раз рассчитать поле зрения и выбрать оптимальный размер (при котором не происходит уменьшения изображения).
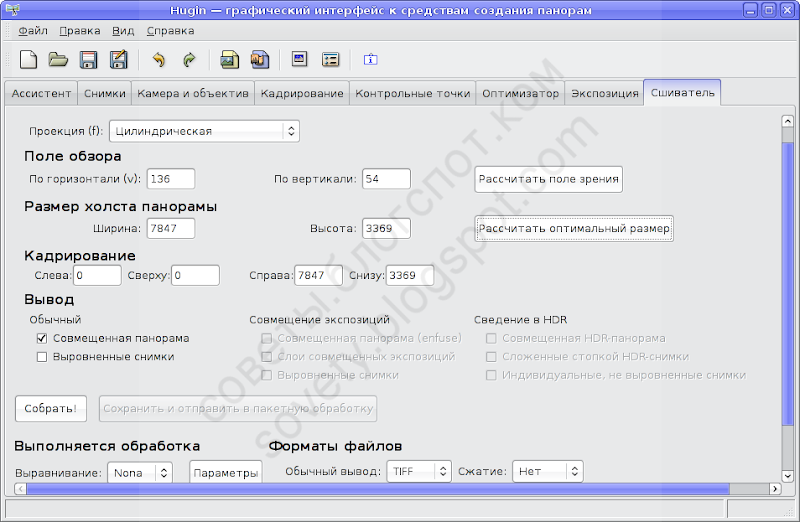
Для просмотра на экране целиком, на мой взгляд, очень хорошо подходит цилиндрическая проекция. Если же планируется просматривать в тех или иных программах просмотра, например в апплете PTViewer, то лучше использовать эквидистантную проекцию (или ту, которую требует программа просмотра). А «рыбий глаз», по-моему, лучше всё равно снимать «рыбьим глазом».
Результат сшивки я всегда сохраняю в формате TIFF, потому что потом его ещё приходится редактировать. Жмём «Собрать», и ждём:
Ждём долго, это, пожалуй, самый долгий вычислительный процесс во всей технологической цепочке. Конец этого процесса выглядит примерно так:
Всё. У нас теперь есть большой файл со сшитой панорамой. Сохраняем проект Хугина и закрываем. Дальше нужно довести сшитую панораму до ума.
Обработка сшитой панорамы
Итак, у нас теперь есть TIFF-файл со сшитой панорамой. Он может быть довольно большим. В этом примере он получился 101 мегабайт. В действительно больших панорамах счёт может пойти на гигабайты. Поэтому я приведу пример, как можно обрезать панораму в редакторе nip2, который может работать даже с изображениями, размер которых превышает размер оперативной памяти.

Вообще, редактор nip2 довольно нетрадиционный. Советую для первого знакомства посмотреть заметку о нём Михаила Конника. Редактор по принципу работы больше похож на электронные таблицы, но работает действительно быстро.
Чтобы обрезать нашу панораму, дважды щёлкнем по ячейке с исходным файлом A1. Откроется новое окно с изображением:
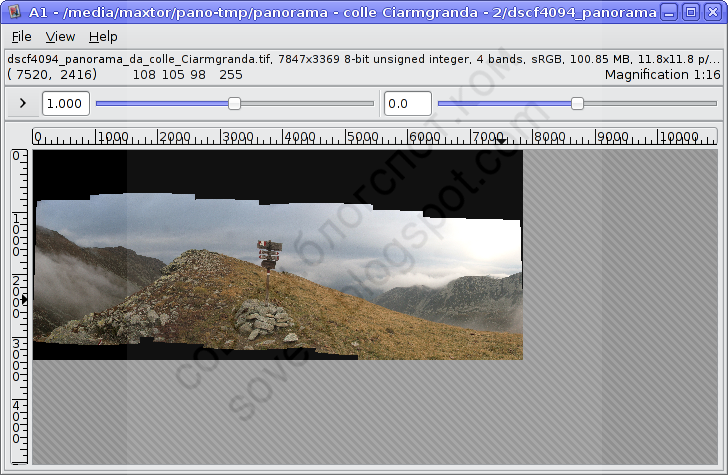
Масштабируем с помощью Ctrl+колёсико мышки. Зажав Ctrl и перетягивая мышку от левого верхнего угла к правому нижнему выделяем прямоугольную область:

Да, выделять прямоугольную область в nip2 нужно именно так: от верхнего левого угла к правому нижнему и зажав Ctrl.
Теперь в главном окне nip2 появляется новая ячейка A2:

Именно содержимое этой ячейки (уже обрезанную панорамe) мы и сохраняем в файл.
В данном случае я обрезал с небольшим запасом, поэтому в одном месте на краю панорамы есть дырка:

По-моему, лучше оставить такую дырку в малозначительном месте, чем отрезать что-то важное в другом месте панорамы. А в малозначительном месте можно помахать клонирующей кистью:
Наконец, сохраняем окончательный вариант панорамы, добавляем геотаги, и любуемся:
Чтобы добавить геотаги потребуется скопировать EXIF-теги из исходных кадров в окончательный вариант панорамы. Я это делают так:
$ exiftool -tagsfromfile первый-кадр.jpg панорама.jpgЧто ещё можно сделать с панорамой?
Одно из самых интересных панорамных сообществ, на мой взгляд, группа Perfect Panoramas на фликере. Туда принимают только те панорамы, в которых модераторы не найдут дефектов.
Есть фотосообщество в ЖЖ, тоже посвященное панорамам. Не помню, как называется.
Панорамам с геотегами — самое место на Panoramio. Хорошие панорамы потом покажут в Google Earth :)
В интернете панорамы можно показывать с помощью апплета PTViewer.
Дополнение 2010-02: со времени написания заметки появился хороший панорамный хостинг pan0.net. На него можно выкладывать как круговые, так и частичные панорамы. Есть флэш-просмотрщик, который можно легко вставлять в блоги.
Перфекционисты и любители монументального искусства могут снимать гигапиксельные панорамы.
Ну и в общем ещё много разных применений этой техники. В том числе и вполне серьёзных.
Успехов!
PS. Я нашёл ещё два сходных руководства на русском языке: Клеим панораму Александра Прокудина и Склейка панорам в Hugin (© БэЖэ). Много учебных материалов доступно на сайте программы Hugin, но, увы, только на английском языке.
20081021
Debian Unstable → Ubunty Hardy → Ubuntu Intrepid (и, наверно, обратно)
Мой ноутбук переживал тяжёлый возрастной кризис. Стал необъяснимо зависать cron (при запуске). Потом стал зависать login. И ещё машина стала иногда зависать при засыпании. В общем, я не исключал и аппаратной проблемы. Зависимость от внешнего охлаждения у машинки уже давняя и прочная (перегревы бывают). А тут, раскурочив, я вынул из её чрева летавший там туда-сюда отвинтившийся непонятно от чего винт. Однако memtest86+ ошибок не находил. В общем, решил попробовать поставить «чистую» систему, чтобы посмотреть, не будет ли чудес и там. Быстренько сбросил образы /home и / на внешний диск (на всякий пожарный,
Поскольку под рукой был диск с Ubuntu 8.04.1, да и давно уже хотелось посмотреть не текущий уровень достижений в убунтустроении, поставил его. Поставилось нормально. /home оставил тот же. Почти всё, что должно работать, вроде работает. Из приятного: если в начале установки попросить показать подробную информацию по релизу, то запускается браузер, и можно что-нибудь в интернете почитать, пока ставится. Инсталятор Debian не видел давно, пока счёт 0:0.
Ещё из приятного, по причине того, что созданный пользователь имел тот же логин и ID, что и раньше, все старые настройки сохранились и замена системы была бы совсем незаметна, если бы не изменились версии кое-каких программ и не пришлось ставить кое-что заново (по мере необходимости). Ну и минимальные отличия вроде того, что Iceweasel здесь зовётся Firefox-ом :) 1:1
Из неприятного. Репозиторий Ubuntu субъективно меньше. Например, мой любимый Simutrans (это такая игрушка, железные дороги строить, паровозики гонять) для Ubuntu не упакован. Собрал из исходников. Да только вот тормозит, время от времени. Хотя за пару дней до этого ровно та же самая версия в Debian работала безукоризненно. Ну да, это развлечения, но для меня лично — уже 2:1. :)
В видеопроигрывателе Totem (через Gstreamer) по-умолчанию как бы играются MIDI (но без звука!). Зато, видимо как раз из-за MIDI время от времени тормозят программы, использующие SDL_mixer (упомянутая выше Simutrans перестаёт тормозить после отключения MIDI). В Debian GStreamer даже не пытался играть MIDI (когда я последний раз пытался), а SDL_mixer не тормозит. 3:1.
Ещё из неприятного, при подключении моего Garmin GPSmap 60Cx к USB порту, в Ubuntu Hardy устройства /dev/ttyUSB0 не создаётся (соответственно, всякие мои скрипты не работают). Как выяснилось, нужно раскоментировать
Зато моя WiFi карточка заработала «из коробки», как и Network Manager. 4:2.
А ещё жене понравилась оболочка для установки-удаления программ. 4:3.
Засыпание-просыпание работает пока без нареканий (то ли время слишком мало прошло, то ли действительно работает). 4:4. Зато кнопки управления яркостью экрана впервые за много лет поменялись местами (т.е. та, которая должна увеличивать яркость — уменьшает, и наоборот). В Debian всё было в порядке, я вообще был уверен, что они аппаратно реализованы. Это конечно мелочь и придирка, но всё же 5:4.
А ещё я постарался посмотреть на всё это с точки зрения «а если бы я был совсем новичок». И пришёл к выводу, что убунту совсем не дружелюбнее дебиан, когда это касается русскоязычных пользователей. Вот, например, по умолчанию пользователь открывает браузер и попадает на сайт техподдержки. Так вот, страница на русском языке там всего одна. Я и по-английски читаю, а кому такую порекомендуешь? Почему на ней нет ссылки на русскую документацию? Не, уж лучше Debian, сайт не такой лощёный, но хоть по-русски куча информации, и найти легко. Да и переводы вроде «разбивка винта» в документации Debian обычно не встречаются. В общем, для русскоязычного пользователя, видимо, Debian в данный момент подходит лучше. Счёт 6:4 в пользу Debian, но арбитр был пристрастен.
Так что жду ненаглядного Lenny, и откатываюсь обратно :)
Update: допишу сюда же об апгрейде до «Бестрепетного тура» (Intrepid Ibex) и об использовании Palm в Убунту. В общем, в отношении апгрейда всё прошло нормально, только папки из закладок стали открываться «Анализатором использования дисков» (
Синхронизация с палмом, как и использование GPS Garmin через GPS, тоже «сломалась» (да, я до сих пор пользуюсь палмом, Tungsten E2). Теперь вместо старого:
PS. На днях, вероятно, опишу, как настроил планшет Wacom Bamboo Fun. Работает. Update: в Intrepid Ibex уже даже и драйвер собирать не надо, распознаётся, работает на ура (кроме стёрки и кнопок), даже теперь стало работать горячее подключение.
dd if=/dev/раздел of=/media/внешнийдиск/backup/файл.img bs=1k conv=noerror,sync) и начал.Поскольку под рукой был диск с Ubuntu 8.04.1, да и давно уже хотелось посмотреть не текущий уровень достижений в убунтустроении, поставил его. Поставилось нормально. /home оставил тот же. Почти всё, что должно работать, вроде работает. Из приятного: если в начале установки попросить показать подробную информацию по релизу, то запускается браузер, и можно что-нибудь в интернете почитать, пока ставится. Инсталятор Debian не видел давно, пока счёт 0:0.
Ещё из приятного, по причине того, что созданный пользователь имел тот же логин и ID, что и раньше, все старые настройки сохранились и замена системы была бы совсем незаметна, если бы не изменились версии кое-каких программ и не пришлось ставить кое-что заново (по мере необходимости). Ну и минимальные отличия вроде того, что Iceweasel здесь зовётся Firefox-ом :) 1:1
Из неприятного. Репозиторий Ubuntu субъективно меньше. Например, мой любимый Simutrans (это такая игрушка, железные дороги строить, паровозики гонять) для Ubuntu не упакован. Собрал из исходников. Да только вот тормозит, время от времени. Хотя за пару дней до этого ровно та же самая версия в Debian работала безукоризненно. Ну да, это развлечения, но для меня лично — уже 2:1. :)
В видеопроигрывателе Totem (через Gstreamer) по-умолчанию как бы играются MIDI (но без звука!). Зато, видимо как раз из-за MIDI время от времени тормозят программы, использующие SDL_mixer (упомянутая выше Simutrans перестаёт тормозить после отключения MIDI). В Debian GStreamer даже не пытался играть MIDI (когда я последний раз пытался), а SDL_mixer не тормозит. 3:1.
Ещё из неприятного, при подключении моего Garmin GPSmap 60Cx к USB порту, в Ubuntu Hardy устройства /dev/ttyUSB0 не создаётся (соответственно, всякие мои скрипты не работают). Как выяснилось, нужно раскоментировать
garmin_gps в /etc/modprobe.d/blacklist. Прогрессивный метод писать в параметрах GPSbabel «-f usb:» у меня лично не работал. 4:1 в пользу Debian.Зато моя WiFi карточка заработала «из коробки», как и Network Manager. 4:2.
А ещё жене понравилась оболочка для установки-удаления программ. 4:3.
Засыпание-просыпание работает пока без нареканий (то ли время слишком мало прошло, то ли действительно работает). 4:4. Зато кнопки управления яркостью экрана впервые за много лет поменялись местами (т.е. та, которая должна увеличивать яркость — уменьшает, и наоборот). В Debian всё было в порядке, я вообще был уверен, что они аппаратно реализованы. Это конечно мелочь и придирка, но всё же 5:4.
А ещё я постарался посмотреть на всё это с точки зрения «а если бы я был совсем новичок». И пришёл к выводу, что убунту совсем не дружелюбнее дебиан, когда это касается русскоязычных пользователей. Вот, например, по умолчанию пользователь открывает браузер и попадает на сайт техподдержки. Так вот, страница на русском языке там всего одна. Я и по-английски читаю, а кому такую порекомендуешь? Почему на ней нет ссылки на русскую документацию? Не, уж лучше Debian, сайт не такой лощёный, но хоть по-русски куча информации, и найти легко. Да и переводы вроде «разбивка винта» в документации Debian обычно не встречаются. В общем, для русскоязычного пользователя, видимо, Debian в данный момент подходит лучше. Счёт 6:4 в пользу Debian, но арбитр был пристрастен.
Так что жду ненаглядного Lenny, и откатываюсь обратно :)
Update: допишу сюда же об апгрейде до «Бестрепетного тура» (Intrepid Ibex) и об использовании Palm в Убунту. В общем, в отношении апгрейда всё прошло нормально, только папки из закладок стали открываться «Анализатором использования дисков» (
baobab). Вылечилось правкой файла ~/.local/share/applications/mimeapps.list, там должно быть inode/directory=nautilus-folder-handler.desktop;, а не что-то иное.Синхронизация с палмом, как и использование GPS Garmin через GPS, тоже «сломалась» (да, я до сих пор пользуюсь палмом, Tungsten E2). Теперь вместо старого:
$ pilot-xfer -p /dev/ttyUSB0 --backup каталог/резервной/копии/$ pilot-xfer -p usb: --backup каталог/резервной/копии/PS. На днях, вероятно, опишу, как настроил планшет Wacom Bamboo Fun. Работает. Update: в Intrepid Ibex уже даже и драйвер собирать не надо, распознаётся, работает на ура (кроме стёрки и кнопок), даже теперь стало работать горячее подключение.
20081017
Обновление скрипта gpxplot
Недавно выкладывал скрипт для визуализации профилей и высоты в GPS треках. Хочу сообщить, что скрипт несколько подновил. В частности, в нём добавилась возможность уменьшать количество точек и возможность рисовать график средствами Google Charts.
Соответственно, сделал и онлайн-версию. Онлайн-версия, в отличие от полной не умеет строить профили высоты и скорости как функции времени. Результат же выглядит примерно так:
Исходники скрипта
Онлайн-версия
Соответственно, сделал и онлайн-версию. Онлайн-версия, в отличие от полной не умеет строить профили высоты и скорости как функции времени. Результат же выглядит примерно так:

Исходники скрипта
Онлайн-версия
Ярлыки:
визуализация данных,
моё,
скрипт,
google,
gps
Подписаться на:
Сообщения (Atom)

{kind=link}
{kind=link}