Продолжаю серию
заметок про GPS. В этот раз расскажу, как, используя GPS, добавить к фотографиям геотаги.
- Геотаг
- — связанная с фотографией информация о географических координатах места съёмки, высоте над уровнем моря и географическом названии местности; технически, геотаги — это дополнительные поля «GPS Latitude», «GPS Longitude» и «GPS Position» в заголовках EXIF.
Если в фотографии присутствует геотаг, то при загрузке её на Flickr или Panoramio она может быть автоматически привязана к карте (на фликере это надо явно разрешить в настройках учётной записи). Умеют обрабатывать геотаги и многие другие сервисы и программы (например, есть плагин для Gallery2).
Для создания геотагов нужно 3 вещи:
- Фотографии с правильными датами и временем в EXIF (для этого лучше ещё до съёмки установить часы фотокамеры по приёмнику GPS).
- GPS-трек, в котором записана траектория перемещения фотоаппарата (фотографа) с указанием времени.
- Программа, которая присваивает фотографии географические координаты из трека. Я расскажу о двух их них: digiKam и HappyCamel (хотя есть ещё gPicSync и другие программы)
Фотографии
Как я уже отметил, часы фотоаппарата лучше синхронизовать с GPS заранее, ещё до съёмки. Если же так случилось, что часы синхронизованы не были, то в дальнейшем придётся установить какое было расхождение часов в двух приборах и указывать его в процессе присвоения геотагов. Здесь и далее я предполагаю, что фотографии уже обработаны и сохранены в формате JPEG (не RAW) и имеют EXIF-заголовки с правильной датой съёмки.
GPS-трек
Подготовка GPS трека вещь более тонкая. Трек должен содержать время для каждой точки. Трек желательно должен быть непрерывным (я выключаю GPS на время стоянок и ночёвок ⇒ треки отдельных переходов нужно объединить в один). Из трека лучше выкинуть «ошибочные» точки (в зонах с плохим приёмом координаты GPS часто «скачут»). Максимальный временной интервал между точками трека должен быть желательно небольшим (иначе придётся полагаться на автоматическую интерполяцию уже в процессе присвоения координат).
В случае навигаторов Garmin это всё означает, что не надо пользоваться функцией «Save track» в приборе. Она не только не сохраняет трек, но и удаляет из него данные о времени, а также сокращает количество точек ради экономии памяти. Подробнее об этом здесь. Для наших целей нужно или брать основной и единственный активный трек из памяти устройства (он обычно называется «ACTIVE LOG #XX») или «сырой» GPX-трек сохраняемый на карточку памяти. А про функцию «Save track» в Garmin лучше забыть и проводить всю обработку треков на компьютере. Скопировать трек на компьютер можно любым удобным способом (некоторые из них я уже описал в предыдущей заметке).
Похоже, самые универсальный и мощный инструмент для обработки треков —
GPSBabel. В случае, если я хочу сразу взять активный трек с устройства Garmin, подключенного к
/dev/ttyUSB0, команда будет выглядеть так:
$ gpsbabel -t -w -i garmin -f /dev/ttyUSB0 -x radius,distance=3K,lat=45.058646,lon=6.907375 -x track,pack -x discard,hdop=3,vdop=3 -x position,distance=5m -x interpolate,time=60 -o gpx -F мойтрек.gpx
где параметры коммандной строки означают следующее:
-i garmin -f /dev/ttyUSB0 говорит брать исходные данные прямо с устройства Garmin подключенного по USB (если исходные данные уже доступны в виде GPX-файла, можно заменить на -i gpx -f исходный-трек.gpx, если исходных GPX-файлов несколько, то можно указать их всех, напримее -i gpx -f 20080621.gpx -f 20080622.gpx -f 20080623.gpx -f 20080624.gpx);
-t -w говорят брать с устройства информацию только о треках (-t) и точках маршрута (-w) — точки маршрута включаю, потому что трек мне пригодится и для других целей;
-x radius,distance=3K,lat=45.058646,lon=6.907375 — это фильтр, отсекающий всё, что не входит в круг радиусом 3 км относительно заданной точки (необязательно);
-x track,pack — этот фильтр объединяет треки отдельных переходов в один большой;
-x discard,hdop=3,vdop=3 — этот фильтр выбрасывает из трека точки, для которых горизонтальная или вертикальная мера ошибки больше 3 (как HDOP и VDOP связаны с метрами), на практике этот фильтр действительно эффективно отсеивает точки внезапно «выскочившие» из траектории, значение «3» эмпирическое, иногда я указываю даже «10»;
-x position,distance=5m — объединяет точки, расстояние между которыми меньше 5 м (короткие остановки);
-x interpolate,time=60 — интерполирует трек так, чтобы между соседними точками было не более 60 секунд (это один из самых полезных фильтров для создания геотагов!);
-o gpx -F мойтрек.gpx — сохраняет результат в файл мойтрек.gpx в формате GPX.
Проверить качество полученного трека можно просмотрев его в какой-нибудь программе. Мне пока больше всего нравится
Viking, он быстро запускается и позволяет подгрузить карты Google под трек, чтобы посмотреть как трек соотносится с местностью. Если трек получился красивый и правильный, переходим к следующему этапу.
Добавление геотагов
Расскажу о двух программах, которые позволяют добавить геотаги: о digiKam (красивый фотоорганайзер с большими возможностями, для добавления геотагов есть графический интерфейс) и о HappyCamel (скрипт для коммандной строки, написанный на Python). Желающие могут легко найти и другие инструменты.
В любом случае, при добавлении геотагов на этом этапе кроме подготовленного трека в формате GPX и фотографий потребуется ещё вспомнить, в каком часовом поясе живём (какое время на фотоаппарате). Здесь нюанс: часовой пояс нужно будет указывать с поправкой на летнее время, то есть, если зимой +03:00, то летом будет +04:00, если зимой +01:00, то летом +02:00.
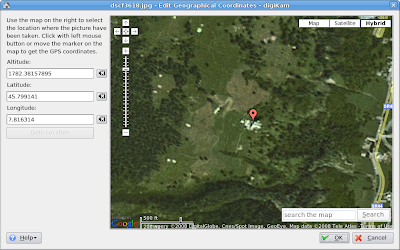
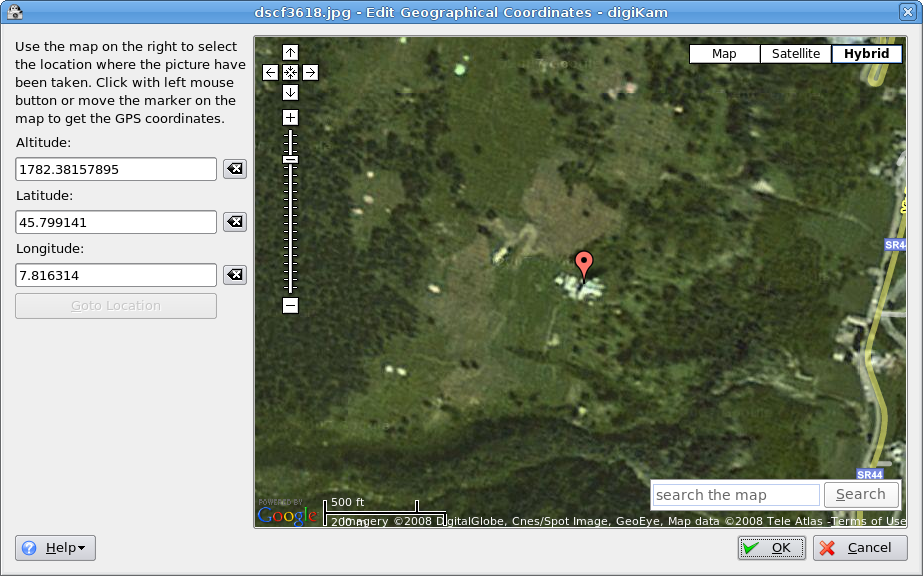
Добавляем геотеги в digiKam
Признаюсь, после долгого перерыва я опять установил digiKam как раз, чтобы попробовать добавить геотаги. К своему удивлению, обнаружил, что как фото-каталогизатор digiKam стала за эти год-два гораздо лучше. Я бы даже сказал лучшим из всех доступных под Linux :-) Настолько, что я его даже оставил и стал пользоваться. Тем более, что работает быстро, структуру моего фотоархива (
ГОД/ГГГГММДД-название-альбома) понимает и не пытается переделывать, метаданные пишет в виде стандартного и открытого IPTC, а по возможностям превосходит всех остальных (F-Spot, Blue Marine, gThumb, Picasa).
Ну а как добавить геотаги, проще показать, чем рассказать:

Добавляем геотеги с помощью HappyCamel
Можно добавить теги и из коммандной строки. Результат получается примерно тот же, только гибкости немного больше. В репозиториях Debian скрипта
HappyCamel ещё нет, но установить его несложно с помощью
$ ./setup.py install --prefix=/префикс/для/установки
(если использовать
checkinstall или
stow, то потом его можно будет легко и просто убрать).
Лучше, конечно, если в системе будет установлен и
exiftool (
libimage-exiftool-perl в Debian). HappyCamel умеет писать в EXIF и без него, но автор рекомендует всё же полагаться на
exiftool.
Чтобы добавить теги, переходим в каталог с фотографиями и выполняем примерно такую команду:
$ happycamel -x y --exiftool=y \
--utc-offset=+02:00 --elevation=2 --use-outside=y \
-t мойтрек.gpx *.jpg
-x y — писать геотэги в EXIF; можно попросить внести туда и географические названия с Geonames.org (-g y);
--exiftool=y — читать и писать EXIF используя exiftool;
--utc-offset=+02:00 — часовой пояс фотоаппарата (с учётом летнего времени!);
--elevation=2 — интерполировать данные о высоте над уровнем моря (не обязательно);
--use-outside=y — фотографии, сделанные до начала или после конца записи трека помечать используя первую и последнюю точки трека соответственно (не обязательно);
-t мойтрек.gpx — трек с траекторией;
*.jpg — no comments :-)
Вот в общем, и всё. Теперь можно загружать фотографии на Flickr или Panoramio. Да, если кому-то интересно, можете посмотреть на
мои фотографии.
Другие заметки про GPS в Linux:
Как добавить геотеги без GPS
Если данных GPS, к сожалению, нет, а геотег добавить надо, то можно сделать так: загрузить фотку на Flickr, поместить её на карту с помощью Flickr Organizr, а потом скачать все помеченные таки образом фотки обратно и по метаданным Flickr добавить уже нормальные геотаги. Подробно это описал Sphinx в заметке
Геотеги Flickr в EXIF. Он же написал скрипт, который этот процесс автоматизирует.
Дополнение: Второй способ. Как верно заметил в комментариях
massalim, можно добавить геотег просто позиционируя фотографию на карте прямо в digiKam (у меня в digiKam 0.9.3 с kipi-plugins 0.1.5 эта возможность есть). В меню выбираем Image → Geolocation → Edit coordinates… и затем просто находим нужное место на карте: