Увы, иногда приходится получать вместо нормального файла изображения документ Word со вставленной в него картинкой. Короткий рецепт, как эту картинку из документа вытащить и получить в виде файла.
1. Открываем документ Word в OpenOffice Writer
2. Сохраняем в формате OpenDocument (.odt)
3. Переименовываем сохранённый файл, изменяя разрешение .odt на .zip (документы OpenOffice, на самом деле, простые zip-архивы)
4. Раскрываем zip-архив и берём готовые файлы изображений из папки Pictures/
20081129
20081127
Подключаем сетевой принтер в GNOME
Задача: подключить сетевой принтер к клиентской машине. Предполагается, что используется GNOME в Debian/Ubuntu.
Решение:
1. Запускаем утилиту настройки принтеров (Система → Администрирование → Печать из меню GNOME или
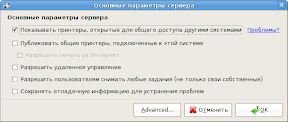
2. Указываем отображать принтеры, подключенные к другим машинам (Сервер → Параметры в утилите настройки, ставим нужную галочку).
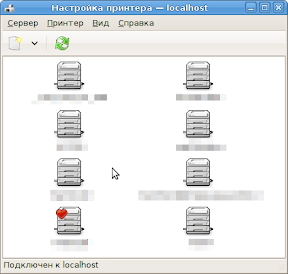
3. В появившемся списке принтеров выбираем принтер по-умолчанию (правой кнопкой из контекстного меню). Чтобы напечатать пробную страницу, дважды щёлкаем по принтеру, и в его свойствах выбираем «Пробная страница».
Вот, в общем, и всё.
Решение:
1. Запускаем утилиту настройки принтеров (Система → Администрирование → Печать из меню GNOME или
sudo system-config-printer).2. Указываем отображать принтеры, подключенные к другим машинам (Сервер → Параметры в утилите настройки, ставим нужную галочку).

3. В появившемся списке принтеров выбираем принтер по-умолчанию (правой кнопкой из контекстного меню). Чтобы напечатать пробную страницу, дважды щёлкаем по принтеру, и в его свойствах выбираем «Пробная страница».

Вот, в общем, и всё.
Ярлыки:
настройка,
начинающим,
debian,
gnome,
ubuntu

20081126
Массовое резервное копирование репозиториев Mercurial
Лёгкость создания репозиториев в системе контроля версий Mercurial (
Соответственно, мой велосипед для резервного копированя всех имеющихся в рабочем каталоге репозиториев имеет два колеса:
По сути скрипт делает две вещи: создаёт (предположительно уникальное) имя для резервной копии репозитория, исходя из его положения на диске, и дальше либо делает клон существующего, удаляет копию, если она уже есть, и клонирует туда заново. Можно же просто копировать. Благо,
Использовать так:
hg) приводит к тому, что начинаешь использовать контроль версий для всего подряд, и количество маленьких репозиториев быстро растёт. При этом они могут лежать где угодно. Соответственно, иногда целесообразно все созданные репозитори ① найти и ② сохранить на будущее. Нахожу по наличию каталога .hg в корне каждого репозитория. Сохранять можно клонированием или простым копированием.Соответственно, мой велосипед для резервного копированя всех имеющихся в рабочем каталоге репозиториев имеет два колеса:
find, чтобы найти ①, и небольшой скрипт backup-hg-repo, чтобы собственно сделать бэкап ②:По сути скрипт делает две вещи: создаёт (предположительно уникальное) имя для резервной копии репозитория, исходя из его положения на диске, и дальше либо делает клон существующего, удаляет копию, если она уже есть, и клонирует туда заново. Можно же просто копировать. Благо,
hg это позволяет (если, конечно, в репозиторий, никто не пишет).#!/bin/sh
# usage: $0 path-to-hg-repository backup-directory
REPO="$1"
BACKUPDIR="$2"
if [ "x$BACKUPDIR" = "x" ] ; then
echo 'specify backup dir'
exit 1
fi
if [ ! -d "$BACKUPDIR" ] ; then
echo "$BACKUPDIR does not exist"
exit 2
fi
BACKUP="$BACKUPDIR/$(dirname "$REPO" | sed 's/^\.\///;s/\/$//;s/[\/_ ]/-/g')/"
REPO=$(dirname "$REPO")
# delete backup repo if it exists
hg status "$BACKUP" && rm -rf "$BACKUP"
hg clone "$REPO" "$BACKUP"
# or copy instead of cloning (if nobody is pushing to $REPO,
# see http://www.selenic.com/mercurial/wiki/index.cgi/BackUp)
# cp -r "$REPO" "$BACKUP"
Использовать так:
$ find . -name '.hg' -type d -exec backup-hg-repo '{}' /путь/по/которому/сохранять/бэкапы \;pull (думаю, это будет быстрее, но не так железобетонно-автоматически, как полный клон), или делать hg bundle -a "$BACKUPDIR/$(dirname ${REPO}).hg" (один сжатый файл истории будет занимать меньше места, но этот способ не сохраняет дополнительные файлы репозитория, вроде hgrc и не совместим с некоторыми расширениями).
Ярлыки:
командная строка,
программирование,
скрипт,
vcs
20081125
Вставка Python-кода в Vim
Как известно, в пайтоне отступ слева («indentation») синтаксически важен. Есть две школы мысли, как набирать его в тексте: табуляциями (количество табуляций — уровень отступа) или пробелами (в этом случае редактор должен обеспечивать раскрытие табуляций до нужного числа пробелов). Главное, эти способы не смешивать.
С одной стороны, я сторонник табуляций, их ширину в редакторе всегда легко изменить, не трогая кода. С другой — Style Guide for Python Code рекомендует делать отбивку четырьмя пробелами. В новых программах я стал использовать четыре пробела, в старых использую табуляции.
Собственно, проблемы здесь две. Первая неспецифична для пайтона, а проявляется всегда при вставке в Vim, запущенный в терминале. Vim попытается автоматически отбить вставляемый код ещё раз. Решение я уже описывал.
Вторая проблема специфична для пайтона. Даже если код был вставлен правильно (с сохранением авторских отступов), но авторские отступы не совпадают с используемыми в программе, код либо не будет работать вообще, либо будет работать неправильно. Выравнивать код с помощью
Выход здесь довольно прост:
P.S. Как легко заметить, пайтон не поощряет повторное использование в стиле copy-paste ;-)
С одной стороны, я сторонник табуляций, их ширину в редакторе всегда легко изменить, не трогая кода. С другой — Style Guide for Python Code рекомендует делать отбивку четырьмя пробелами. В новых программах я стал использовать четыре пробела, в старых использую табуляции.
Проблемы начинаются при попытке вставить чужой код в свой проект. С высокой степенью вероятности, он или использует другой способ ввода отступов, или другую ширину отступа.Лирическое отступление
В целом, в Vim набирать код Python удобно: поддерживается как режим с табуляциями, так и режим с пробелами. В последнем случае нужно установить опциюexpandtab. Автоматические отступы для Python поддерживаются.
Часто пригождается: чтобы сдвинуть блок текста влево или вправо:Shift-V, выделение блока,<<или>>соответственно.
Задать желаемую ширину табуляции и ширину сдвига можно опциямиtabstopиshiftwidthсоответственно, например:Настройки файла можно прописать в его:set ts=4 sw=4modeline.
Собственно, проблемы здесь две. Первая неспецифична для пайтона, а проявляется всегда при вставке в Vim, запущенный в терминале. Vim попытается автоматически отбить вставляемый код ещё раз. Решение я уже описывал.
:set paste.Вторая проблема специфична для пайтона. Даже если код был вставлен правильно (с сохранением авторских отступов), но авторские отступы не совпадают с используемыми в программе, код либо не будет работать вообще, либо будет работать неправильно. Выравнивать код с помощью
<< и >> далеко не всегда удобно.Выход здесь довольно прост:
- (опционально) временно отключить
expandtab, если используется; - преобразовать авторские пробелы в табуляции, для этого выделяем нужный блок и делаем
:retab!5, где аргумент («5») — авторская ширина отступа; - (опционально) при использовании
expandtab, включить его обратно, а «авторские» табуляции заменить на нужное число пробелов (:s#\t# #g).
P.S. Как легко заметить, пайтон не поощряет повторное использование в стиле copy-paste ;-)
Ярлыки:
программирование,
python,
vim
20081121
XPDF для предварительного просмотра LaTeX
При редактировании документов LaTeX я обычно пользуюсь для предварительного просмотра
Вот ещё несколько менее известных, но полезных при таком использовании
xpdf. Несмотря на его спартанский интерфейс, тому есть пара весомых причин:- он запускается быстрее всех других PDF-смотрелок, это удобно при использовании из командной строки;
- он умеет принудительно перезагружать документ (клавиша
R).
Вот ещё несколько менее известных, но полезных при таком использовании
xpdf возможностей:- у
xpdfесть удобные клавишы для быстрого переключения масштаба (Z— чтобы уместить страницу,W— уместить по ширине); - включить полноэкранный режим можно сочетанием
ALT-F; - указать желаемый масштаб можно прямо из командной строки:
илиxpdf -z page myfile.pdfxpdf -z width myfile.pdf - и самое главное, можно открыть документ сразу на нужной странице:
xpdf myfile.pdf номерстраницы
Ярлыки:
командная строка,
latex,
PDF
20081118
Встраиваем субтитры в AVI (hardsubs)
Как сделать субтитры? Очень просто: ставим
В идеале, так их и надо распространять. Отдельным файлом. Однако зрителю придётся озаботится установкой правильных шрифтов, указать правильную кодировку субтитров в своём плеере, и вообще, пользоваться плеером, который умеет показывать субтитры.
Можно же встроить субтитры прямо в видео (пережать видео так, чтобы субтитры стали частью видеокартинки). Тогда они будут правильно видны у любого зрителя (в т.ч. на всякию ютубах). Правда, увы, их нельзя будет отключить или как-то изменить.
Чтобы встроить субтитры в видео, вначале подбираем нужные параметры их воспроизведения, например, так:
gaupol, запускаем, выбираем File→New, сохраняем в пустой файл mysubs.srt, подключаем видео (File→Select Video, этот пункт недоступен, пока мы не сохраним проект), после этого аккуратно вписываем все субтитры, иногда нажимая кнопку Play, чтобы посмотреть на результат и заметить время. Спустя некоторое время у нас окажется готовый файл с субтитрами mysubs.srt.В идеале, так их и надо распространять. Отдельным файлом. Однако зрителю придётся озаботится установкой правильных шрифтов, указать правильную кодировку субтитров в своём плеере, и вообще, пользоваться плеером, который умеет показывать субтитры.
Можно же встроить субтитры прямо в видео (пережать видео так, чтобы субтитры стали частью видеокартинки). Тогда они будут правильно видны у любого зрителя (в т.ч. на всякию ютубах). Правда, увы, их нельзя будет отключить или как-то изменить.
Чтобы встроить субтитры в видео, вначале подбираем нужные параметры их воспроизведения, например, так:
$ mplayer -subwidth 75 -subcp utf8 -subfont-text-scale 3 -sub mysubs.srt myvideo.aviman mplayer. После этого перекодируем видеофайл:$ mencoder -oac mp3lame -ovc lavc -lavcopts vcodec=mpeg4:vbitrate=2000 myvideo.avi -subwidth 75 -subcp utf8 -subfont-text-scale 3 -sub mysubs.srt -o myvideo-with-hardsubs.avi
Ярлыки:
видео,
командная строка
До стабильного релиза Debian осталось…
Помню, как накануне выхода Intrepid Ibex весь инет пестрел картинками: осталось столько-то дней. Но мы-то ждём безглючного Lenny! А он будет готов тогда, когда будет готов, т.е. когда будут закрыты все баги. Итак, веселья ради, мой счётчик*:
Вставляется так:
Пример здесь: Debian RC-bugs countdown
Кстати, говорят, уже первый релиз-кандидат инсталлятора вышел…
* В RSS-аггрегаторах может не показываться, вставляется IFRAME-ом.
Дополнение: вышел, вышел уже родимый Lenny. Просто праздник!
Вставляется так:
Пример здесь: Debian RC-bugs countdown
Кстати, говорят, уже первый релиз-кандидат инсталлятора вышел…
* В RSS-аггрегаторах может не показываться, вставляется IFRAME-ом.
Дополнение: вышел, вышел уже родимый Lenny. Просто праздник!
Ярлыки:
debian
20081114
Статья: Как сделать GNU/Linux популярным
Интересная статья «Как сделать популярный дистрибутив». Основной тезис, что дело не в программном обеспечении или тех или иных свойствах дистрибутива, а в доступности коммерческих (т.е. доступных любому) услуг по установке и настройке GNU/Linux для конечного пользователя. Мне тезис кажется правильным.
Думаю, многие бы пользователи с радостью бы воспользовались такой услугой, ведь при этом за фиксированную плату они получат надёжный компьютер для интернета, редактирования документов, фото, просмотра видео и т.д., и смогут забыть про вирусы. А барьер по переходу от свежеустановленного дистрибутива (любого) до такой настроенной и работающей как надо пользователю системы обычно как раз и есть та причина, по которой простому человеку линукс я никогда не рекомендую. После же преодоления таких препятствий, как правило, система может использоваться очень долго практически без поддержки (так большинство пользователей и поступает).
Думаю, многие бы пользователи с радостью бы воспользовались такой услугой, ведь при этом за фиксированную плату они получат надёжный компьютер для интернета, редактирования документов, фото, просмотра видео и т.д., и смогут забыть про вирусы. А барьер по переходу от свежеустановленного дистрибутива (любого) до такой настроенной и работающей как надо пользователю системы обычно как раз и есть та причина, по которой простому человеку линукс я никогда не рекомендую. После же преодоления таких препятствий, как правило, система может использоваться очень долго практически без поддержки (так большинство пользователей и поступает).
Ярлыки:
ссылки
20081112
Удалённое журналирование домашнего маршрутизатора
Матёрые сисадмины (я себя к ним не отношу) это и так знают, но простым пользователям это тоже может быть полезно. Бывает, что с домашней точкой доступа/маршрутизатором/DSL-модемом что-то случается и надо разобраться. Доступ к таким устройствам обычно только через веб-интерфейс. И даже если там включено журналирование, читать их журнал событий («лог») через веб-интерфейс не всегда удобно, да и время его хранения там не регулируется. К счастью, его можно перенаправить на нормальную GNU/Linux машину и сохранить в общем системном журнале.
Последовательность действий.
1. Включаем удалённое журналирование на маршрутизаторе. На моём Linksys-е, например, в веб-интерфейсе я выбираю Administration/Reporting/Syslog IP Address. Вводим IP-адрес своей машины. Чтобы узнать адрес своей машины:
Понятное дело, что IP-адрес машины, сохраняющий журнал, предпочтителен статический, иначе придётся менять настройку каждый раз, когда меняется адрес.
2. На локальной машине, где будет писаться лог, требуем от syslog-а принимать логи от удалённых машин. Эта возможность по-умолчанию выключена, включается опцией -r при запуске сервера. В Debian-системах редактируем файл /etc/default/syslogd, и добавляем опцию в переменную SYSLOGD:
2б. Для удобства, можно прописать IP-адрес маршрутизатора в файл /etc/hosts, что-нибудь вроде
тогда в логах записи полученные с него записи будут помечаться именем «коробочки», а не её IP-адресом.
3. Перезапускаем syslogd:
4. Журнал маршрутизатора теперь будет добавляться в /var/log/messages:
Последовательность действий.
1. Включаем удалённое журналирование на маршрутизаторе. На моём Linksys-е, например, в веб-интерфейсе я выбираю Administration/Reporting/Syslog IP Address. Вводим IP-адрес своей машины. Чтобы узнать адрес своей машины:
$ ip addr | grep 'inet\>'
Понятное дело, что IP-адрес машины, сохраняющий журнал, предпочтителен статический, иначе придётся менять настройку каждый раз, когда меняется адрес.
2. На локальной машине, где будет писаться лог, требуем от syslog-а принимать логи от удалённых машин. Эта возможность по-умолчанию выключена, включается опцией -r при запуске сервера. В Debian-системах редактируем файл /etc/default/syslogd, и добавляем опцию в переменную SYSLOGD:
SYSLOGD="-r"
2б. Для удобства, можно прописать IP-адрес маршрутизатора в файл /etc/hosts, что-нибудь вроде
192.168.1.1 router
тогда в логах записи полученные с него записи будут помечаться именем «коробочки», а не её IP-адресом.
3. Перезапускаем syslogd:
$ sudo invoke-rc.d sysklogd restart
4. Журнал маршрутизатора теперь будет добавляться в /var/log/messages:
$ tail -f /var/log/messages | grep router
Nov 12 11:22:31 router secondary DNS address 193.70.152.25
Nov 12 11:22:31 router run_program(/etc/ppp/ip-up)
…
20081111
Python на службе науки (черновик)
Не знаю, соберусь ли это дело систематизировать, пока буду просто добавлять в этот пост короткие «рецепты» по применению Python в околонаучных целях (создание отчётов, построение графиков и тому подобное). Поживём-увидим.
Преобразование числа из экспоненциальной формы (например, –1.2e+003) в формулу LaTeX (например, -1.2 10³). Регулярное выражение:
Прозрачные/полупрозрачные легенды (подписи) в графиках
Формулы LaTeX в подписях и надписях в
Открытый вопрос — как делать русские подписи в Дополнение: вопрос решился сам. См. заметку Русские буквы в matplotlib/pylab.
Произвольная надпись, выровненная по центру —
Дана пара массивов (списков)
Из полученных пар выделить опять отдельные массивы
Кусочно-линейная интерполяция зависимости
Транспонирование двумерного массива — проще всего
Линейная регрессия (аналогично — фиттирование более сложных функций, модифицировать количество параметров и вычисление ошибки в
Интегрирование системы обыкновенных дифференциальных уравнений (ОДУ):
Чтобы построить график полученного решения (2D), транспонируем
Преобразование числа из экспоненциальной формы (например, –1.2e+003) в формулу LaTeX (например, -1.2 10³). Регулярное выражение:
>>> import re
>>> re.sub('([\d.+-]+)[Ee]\+?([-]?)0*([\d]+)', '\\1 \\cdot 10^{\\2\\3} ','-1.2e+003')
'-1.2 \\cdot 10^{3} '
Прозрачные/полупрозрачные легенды (подписи) в графиках
pylab:l=legend()
l.get_frame().set_alpha(0.2)
Формулы LaTeX в подписях и надписях в
pylab: просто заключить нужный фрагмент надписи в $…$, например '$\rho$'.pylab?Произвольная надпись, выровненная по центру —
(xlim()[0]+xlim()[1])*0.5, ha="center" — нижнего края — lim()[0], va="bottom") — графика в pylab:text((xlim()[0]+xlim()[1])*0.5,ylim()[0],"your message",ha="center",va="bottom",fontsize=10)
Дана пара массивов (списков)
t и x с временем измерения и измеренной величиной, отобрать только те пары время-значение, которые попадают в заданный временной интервал [t0, t1] (или какому другому условию):xt=[ pair for pair in zip(x,t) if t0 <= pair[0] <= t1 ]
Из полученных пар выделить опять отдельные массивы
t и x:t=[pair[0] for pair in tx]или с использованием
x=[pair[1] for pair in tx]
array из scipy:t,x=array(tx)[:,0],array(tx)[:,1]
Кусочно-линейная интерполяция зависимости
t→x на другом наборе точек t2 (тоже список, как и t):from scipy import interp
interp(t2,t,x)
Транспонирование двумерного массива — проще всего
array([[1,2,],[3,4]]).transpose().Линейная регрессия (аналогично — фиттирование более сложных функций, модифицировать количество параметров и вычисление ошибки в
residual()). Как и прежде, предполагаю, что точки для фиттирования заданы в массивах t и x:from scipy import array
from scipy.optimize import leastsq
def residual(params,t,x):
a,b=params
x_ab=array([a*x=t_i+b for t_i in t])
return x_ab-x
[a,b],ier=leastsq(residual,(1,1),args=(t,x))
Интегрирование системы обыкновенных дифференциальных уравнений (ОДУ):
from scipy import linspace, array
from scipy.integrate import odeint
def dotu(u,t0):
"расчёт производных в момент времени t0"
x,y,z=u # вектор переменных
sigma,rho,beta=10,28,8.0/3 # параметры модели
dotx=sigma*(y-x)
doty=x*(rho-z)-y
dotz=x*y-beta*z
return [dotx,doty,dotz]
t=linspace(0,50,1e4) # точки интегрирования
u0=[-5,-5,1] # начальное условие
u=odeint(dotu,u0,t) # решение
Чтобы построить график полученного решения (2D), транспонируем
u и строим как обычно:from pylab import plot, show
u=array(u).transpose()
plot(u[1],u[2]) # строим фазовый портрет y-z
show()
20081107
Приёмы работы в коммандной строке *NIX
По мотивам дискуссии на слэшдоте. Всякие полезные, занятные и совсем бесполезные мелочи, позволяющие сделать работу в коммандной строке удобнее и приятнее. Кое-что добавил уже от себя. Многим это, конечно, и так известно, но коллективный опыт всегда больше. Я для себя кое-что почерпнул.
- Началось с упоминания о
write, которая позволяет слать сообщения другим пользователям системы.
Хотя, если права позволяют, можно просто писать$ w
…
sergey pts/1 :0.0 11:34 3.00s 0.18s 0.18s bash
$ write sergey pts/1
hi there!
^D$ echo '^LAll files deleted.' > /dev/pts/1 TAB-TAB-TAB:-)
- Не обошлось без шуток. Мне понравился «коан»:
И «про уток»:$ grep '' /dev/null$ du -cks - А
screenпозволяет подключаться и отключаться к виртуальному терминалу, который работает даже если выйти из системы, имеет кучу применений, от запуска «долгоиграющих» процессов на удалённых машинах до экстремального программирования; также очень полезен для создания «общего» терминала (screen -x), можно видеть, что делает другой человек, или показывать ему то, что делаешь. На удалённой машине обычно запускаю так:
Список виртуальных терминалов:$ screen -RD^Aw. Выбор терминала:^Aцифра. Отсоединися отscreen-а (не закрывая его терминалы):^Ad
cd -, чтобы вернуться в предыдущий каталог (доcd) иcd `pwd -P`, чтобы перейти по настоящему пути (если пришёл по символической ссылке). Ещё полезныpushdиpopd(запомнить текущий каталог и потом в него вернуться).
history | grep шаблон, чтобы вспомнить, что уже делал.^Rфрагмент-команды^R^R^R…, чтобы найти и повторить ранее выполненную команду.^Nи^Pчтобы прокручивать историюbashвперёд и назад.
- Чтобы повторить последнюю команду:
И при редактировании команды —$ !!ESC., чтобы подставить последний аргумент последней команды. В эту же категорию попадает ещё целая пачка трюков (man bash,/^HISTORY EXPANSION).
- Если в режиме поиска команды нажать
^O, то будет исполнена текущая команда из истории и после этого будет набрана следующая команда из истории. Можно автоматизировать весь цикл редактирование-компиляция-исполнение. Проще объяснить на примере:$ vi foo.c
$ gcc -o foo{,.c}
$ ./foo
$ ^Rvi^O^O^O^O^O… - Для любителей
viможно переключить сочетания клавиш
после этого ESC чтобы перейти в коммандный режим и режима вставки,$ set -o vik/j, чтобы прокручивать историю команд,/шаблонENTER, иn/N, чтобы искать по истории. Если честно, хотя и и пользуюсь постоянноvim, вbashпо-умолчанию всё равно Emacs-овские сочетания…
META-tвbash, чтобы поменять местами аргументы.
^Sи^Q, чтобы приостановить и продолжить вывод в терминал («пауза»).
resetобычно приходится набирать вслепую (после неудачного вывода бинарного файла в stdout). Чаще достаточно^L.
sshи много-много-много его применений.-XCдля запуска иксовых приложений на удалённой машине с локальным X-сервером.-D,-Lи-Rдля создания защищённых тунелей. Требует отдельного обсуждения.
sftp, имитация FTP-клиента поверх SSH, иsshfsдля подключения удалённой файловой системы поверх SSH (я бы добавил сюдаscpиrsync).
wc -l, чтобы подсчитать количество строк.nl, чтобы добавить номера строк.
sortдля сортировки строк.sort -n— числовая сортировка.
… | rev | sort | rev, чтобы сгруппировать строки по окончаниям.
du -sh * | sort -nнеплохая замена графическомуbaobab(точнее наоборот).
head -количествострокиtail -количествострокдля печати начала и конца файла,tail -f, чтобы следить за файлом, который ещё пишется (например, лог). Полезный вариант:tail -F возможно-несуществующий-файл.
strings, чтобы увидеть человеко-читаемые строки, встречающиеся в файле. См. пример в предыдущем посте.
grep, чтобы отобрать только нужные строчки,… | grep шаблон. Мне часто полезны опции-r(рекурсивно во вложенных подкаталогах) и-i(без учёта регистра). Да,grepподдерживает также опцию--color(нагляднее).
awkдля того, чтобы разбить строчку на поля и вытащить только нужные.… | awk -F'разделитель' '{print $номер-поля;}'
В простых случая можно использовать$ echo "a,b,c" | awk -F',' '{print $2;}'cut -d 'разделитель' -f список-полей:$ echo 'a,b,c' | cut -d ',' -f 2- Обратные апострофы (
`команда`или$(команда)) подставляют результат выполнения команды.$ NOW=$(date -u)
…
$ echo $NOW
Птн Ноя 7 12:17:07 UTC 2008 - Выполение задания в назначенное время (один раз):
Говорящий будильник:$ echo 'команда' | at время
Такой вот одноразовый$ echo 'for i in `seq 1 10`; do echo wake up, internet was updated | festival --tts ; done;' | at 08:00cron.
findочень стоит того, чтобы научиться ей пользоваться. Особенно полезна опция-exec команда, в которой {} заменяет имя найденного файла \;. Для меня стало открытием, что-execможно использовать также в качестве условия для выбора файлов:$ find . -exec grep -q 'шаблон' {} \; -printecho *вместоls.ls -vдля «правильной» сортировки пронумерованных файлов (12.txt после 2.txt).ls -tgoпокажет недавно изменённые файлы первыми.
- Мне очень нравятся фигурные скобки в
bash. Так можно писать:
вместо$ gcc -o foo{,.c}
$ convert /длинный/путь/к/image.{eps,jpg}$ gcc -o foo foo.c
$ convert /длинный/путь/к/image.eps /длинный/путь/к/image.jpg - Управление процессами:
^Z,bg,fg,jobs,kill %номерзадачи. И тогдаpsнужен гораздо реже. Аhtop, кстати, удобнее, чем простоtop.
- Раскрытие переменных в
bash:${var%ending-to-remove}newending,${var/find/replace},${var//find/replace-all},${var#prefix-to-remove}.
- Циклы в
bash:for f in * ; do команды ; doneчтобы обработать все файлы (*),for i in `seq 1 10` ; do команды ; doneчтобы перебрать всеiот 1 до 10. В скриптах удобно использовать неявные циклы видаwhile [ $# -gt 0 ] ; do arg=$1; shift; … ; done.
- Широко известно про
ddдля создания образов дисков, их бэкапа и восстановления.
Менее известный приём:# dd if=/dev/раздел of=/media/backup/образ-раздела bs=1k conv=noerror,synckillall -USR1 dd, чтобы увидеть, сколько уже сделано.
lsof /media/том, чтобы узнать, какой процесс использует файлы на нежелающем отсоединяться диске. Может пригодится и для решения проблем с файлами устройств (/dev/что-нибудь).
Другой вариант —fuser -v /media/том. Тоже очень удобно.
eject, чтобы выдвинуть подставку для кофе.
cal 11 2008и мы вспоминаем, что сегодня пятница.dateи узнаём, который час.
- Из всевозможных «калькуляторов» под рукой почти всегда будет вот этот:
Ещё традиционный вариант для интерактивного использования —$ awk 'BEGIN{ print exp(1)+2^(1.0/3); }'bc -l. В нём, правда, нестандартные названия функций:s(x)— синус,c(x)— косинус,a(x)— арктангенс,l(x)— натуральный логарифм,e(x)— экспонента,x^n— целая степень. Предыдущее выражение можно посчитать так:
А целые числа умеет складывать и$ bc -l
...
e(1)+e((1/3)*l(2))
3.97820287835391840011bash:echo $((2+2)).
time командачтобы засечь время выполнения задачи.
ulimit -m размер-памяти-в-килобайтахограничить максимальный размер памяти процессов, вызываемых из текущей оболочки. Вариант:-v размер-памяти-в-килобайтахдля ограничения размера виртуальной памяти. Полезно, если есть опасения, что процесс слишком жадный.
nice -n +10 командавыполнить команду с пониженным на 10 приоритетом. Полезно, если команда работает долго, требует много процессорного времени, а оно нужно и для другого.
- Доб. 2008-11-26: чтобы после поиска по истории вернуться к последним коммандам,
ESC >.
cut, bc -l и fuser.
Ярлыки:
командная строка
20081106
Удаление потайных ID3 тегов вроде www.mp3-ogg.ru
Столкнулся с тем, что в mp3 бывают скрытые «неудаляемые» теги. В частности, в интернет-обращении находятся файлы, в которых в поле жанр указано «www.mp3-ogg.ru». И сколько бы я ни прописывал правильные теги в EasyTAG, или даже пытался удалять все (ID3v1 и ID3v2) теги из такого файла (в EasyTAG или с помощью
Похоже, это связано с так называемыми APETAGS, будь они неладны. Только старый добрый
Как заметил наблюдательный народ, потайные теги расположены в конце файла. Убедиться в этом можно, например, так:
id3v2 -D file.mp3), при добавлении файла в библиотеку Rhythmbox поганое «www.mp3-ogg.ru» всё равно вылазит.Похоже, это связано с так называемыми APETAGS, будь они неладны. Только старый добрый
mpg321 показывает нормальные ID3v2/ID3v1 теги.Как заметил наблюдательный народ, потайные теги расположены в конце файла. Убедиться в этом можно, например, так:
$ strings test.mp3 | tail -14
APETAGEX
TITLE
ARTIST
ALBUM
YEAR
2007,
COMMENT
GENRE
www.mp3-ogg.ru
COPYRIGHT
Make Love Not War
TRACKNUMBER
1APETAGEX
2007$ tagwipe.py test.mp3
Ярлыки:
звук,
командная строка,
скрипт,
mp3
Подписаться на:
Сообщения (Atom)
