Многие читали
Beating the Averages Пола Грэхэма (есть
перевод). Он использовал Lisp, и считает, что именно поэтому создал самое удачное веб-приложение (которое потом превратилось в Yahoo! Store). Прекрасно!
А вот что реально уже готово и можно использовать
прямо сейчас? Я решил не зацикливаться на Хаскеле, и вспомнил, что есть ещё Erlang, Caml, Scala, Scheme, Lisp. Стоило только начать поиски, и я нашёл много интересного. Делюсь находками.
1. Язык программирования
Erlang и каркас для разработки веб-приложений
Nitrogen. Кстати, сайт Nitrogen на нём же, видимо, и работает. Рекомендую посмотреть видео:
Видео: возможности Nitrogen (дек. 2008) (.mov)
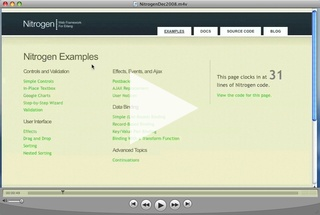
Обратите внимание на счётчик числа строк, нужных, чтобы запрограммировать страницу (такой счётчик есть и на всех страницах сайта Nitrogen). Число, как правило, двузначное. Меня лично поразило
вот это — запуск долгоиграющих процессов на сервере. 31 строчка! Чтобы сделать подобное на Python и Django, мне пришлось попыхтеть.
Кроме Nitrogen, для Erlang есть ещё
Erlyweb и
Erlang Web.
2. Язык программирования
Haskell и сервер приложений
Happstack. Самое приятное, что проект хоть ещё и молодой, но уже
работающий. На нём сделан
Happstack-tutorial, на нём работает
Patch-tag.com. Первые энтузиасты даже делают на нём
свои блоги.
Запустить его на своей машине оказалось не очень трудно. И он
работает. Но всё же, я чувствую, мне потребуется время, чтобы с ним более-менее разобраться. Документация, с точки зрения новичка, конечно, уступает документации Django.
Основная отличительная черта Happstack: реляционная база данных ему не нужна. Можно пользоваться теми структурами данных, которые наиболее удобны. Возможность с одной стороны спорная, полагаться на неё страшно, с другой — весьма интересная.
Вот маленькая презентация Happstack:
Но и не Happstack единым. Читаем
Is Haskell a Good Choice for Web Applications?. Весьма обнадёживает. Исходник работающего сайта — в подарок.
3. Язык программирования
Scala (гибридный функциональный язык программирований для виртуальной машины Java) и каркас для веб-приложений
Lift. Можно посмотреть на его
демо.
Интересно, что буквально на днях Гугл объявил поддержку Java на AppEgnine, и народные умельцы уже
используют там Scala. Более того, точно так же
на AppEngine запустили и Lift.
Scala — по-итальянски лестница. Думаю, игра слов scala — lift теперь всем понятна.
4. Язык программирования
Caml и каркас для веб-приложений
Ocsigen. Точнее, как я понял, Ocsigen — это веб-сервер, а каркас для веб-приложений называется Eliom. И есть ещё набор библиотек Ocsimore. Однако это детали.
Интересные особенности Ocsigen: валидность XHTML документа гарантируется на уровне типов языка, активно используется стиль
отложенных вычислений, управление сессиями, URL-схемами и параметрами страниц автоматическое.
В репозитариях основных дистрибутивов Ocsigen уже есть, так что приступить к использованию будет легко. Вот, например,
вики-органайзер написанный с использованием Ocsigen. Разработчики тоже не стесняются использовать детище
для своих сайтов. Добрый знак. Работает, говорят,
очень быстро. Однако будем помнить, что это прежде всего исследовательский проект.
Читая сайт Ocsigen, нашёл и совершенно удивительный проект. Немного не в тему, но очень здорово: O'Browser, написанная на Javascript виртуальная машина для байт-кода OCaml. Что это значит? Значит, что код на OCaml можно встраивать в веб-страницы! Вот, например, клон Boulderdash. Что-то подобное есть и для Haskell.
5. Язык программирования
Scheme и каркас для веб-приложений
LeftParen. Документация выглядит толково. К сожалению, не нашёл сайтов, которые его используют. Или какого-нибудь демонстрационного сайта.
Вообще-то LeftParen построен вокруг уже довольно развитой инфраструктуры для веб-программирования в PLT Scheme. И её вполне можно использовать непосредственно, см.
документацию и
учебник.
Для Scheme есть ещё
Icing.
6. Язык программирования
Lisp и веб-каркас
Weblocks. Сайт и документация очень мне понравились. Если бы я писал на Лиспе, начал бы, наверное, с этого каркаса. Вот
демонстрация.
Есть ещё
KPAX (это не русское слово, просто такое смешное сокращение!). Пишут, что уже давно и серьёзно используется, но документация страдает. Для Лиспа есть ещё
UnCommon Web,
BKNR.
7. Ещё один диалект Лиспа — язык программирования
Clojure, как и Scala рассчитан на использование на платформе JVM. Надо ли говорить, что и для него есть веб-каркас:
Compojure. И на AppEngine его тоже оперативно
запустили.
Вот так-то. Сколько всего, оказывается. Глаза разбегаются.
Созвучен этой заметке будет вот
этот пост.









{kind=link}